Journal of Signal Processing Systems ( IF 1.8 ) Pub Date : 2022-06-01 , DOI: 10.1007/s11265-022-01765-4 Fang Liu , Yanxiang He , Jing He , Xing Gao , Feihu Huang
|
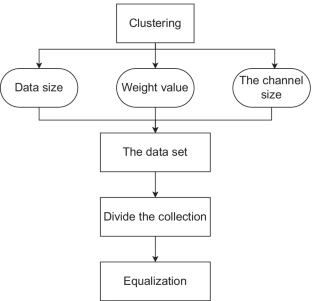
In today’s data age, the big data processing analysis framework plays an important role in mass information processing, along with the increasing of massive data. “Sharing Data” is proposed to enhance the performance of data processing through structured data scheduling. However, such approach makes the higher communication cost and buffer cost for the extra data copy and buffering. Hence, in the big data analysis environment, this paper uses based on the correlation of data, Dynamic Cluster Scheduling Algorithm(DCSA) is proposed for parallel optimization of big data tasks. Firstly, a dynamic data queue based on the server’s request database is generated. The priority of data item and size of data item are as the considerations of dynamic data queue for data clustering association. And then the weights are introduced, the dynamic data item is made equalization to provide the basis for the multi-channel optimal scheduling. Secondly, according to the relevance of the data items, the mechanism of data optimized placement is used to make the data which are aggregated in the same frame. After the placement is completed, the dynamic data is uniformly scheduled to minimize the cost at the time of migration, with the local characteristics of the data item as constraints. Through the target iteration, the optimal scheduling scheme is adjusted, and finally to achieve multi-channel optimal scheduling. Experiments show that the proposed method enables dynamic data to achieve optimal scheduling.
中文翻译:
基于动态聚类调度算法的大数据并行调度优化
在当今数据时代,随着海量数据的不断增加,大数据处理分析框架在海量信息处理中发挥着重要作用。提出了“共享数据”,通过结构化的数据调度来提高数据处理的性能。然而,这种方法使得额外的数据复制和缓冲的通信成本和缓冲成本更高。因此,在大数据分析环境下,本文采用基于数据相关性的动态集群调度算法(DCSA)对大数据任务进行并行优化。首先,根据服务器的请求数据库生成动态数据队列。数据项的优先级和数据项的大小作为数据聚类关联动态数据队列的考虑。然后引入权重,对动态数据项进行均衡处理,为多路优化调度提供依据。其次,根据数据项的相关性,采用数据优化放置机制,使数据在同一帧中聚合。放置完成后,以数据项的局部特性为约束,对动态数据进行统一调度,以最小化迁移时的成本。通过目标迭代,调整最优调度方案,最终实现多通道最优调度。实验表明,该方法能够使动态数据实现最优调度。采用数据优化放置机制,使数据聚合在同一帧中。放置完成后,以数据项的局部特性为约束,对动态数据进行统一调度,以最小化迁移时的成本。通过目标迭代,调整最优调度方案,最终实现多通道最优调度。实验表明,该方法能够使动态数据实现最优调度。采用数据优化放置机制,使数据聚合在同一帧中。放置完成后,以数据项的局部特性为约束,对动态数据进行统一调度,以最小化迁移时的成本。通过目标迭代,调整最优调度方案,最终实现多通道最优调度。实验表明,该方法能够使动态数据实现最优调度。最终实现多通道优化调度。实验表明,该方法能够使动态数据实现最优调度。最终实现多通道优化调度。实验表明,该方法能够使动态数据实现最优调度。


























 京公网安备 11010802027423号
京公网安备 11010802027423号