Journal of Signal Processing Systems ( IF 1.8 ) Pub Date : 2022-05-09 , DOI: 10.1007/s11265-022-01770-7 Ruqiao Liu 1, 2 , Yi Zhou 1 , Hongqing Liu 1 , Xinmeng Xu 2, 3 , Jie Jia 2 , Binbin Chen 2
|
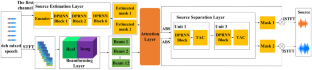
Speech separation is the key to many speech backend tasks, like multi-speaker speech recognition. In recent years, with the development and aid of deep learning technology, many single-channel speech separation models have shown good performance in weak reverberant environment. However, with the presence of reverberation, the multi-channel speech separation model still has greater advantages. Among them, the deep neural network (DNN) based beamformers (also known as neural beamformers) have achieved significant improvements in separation quality. The current neural beamformers can’t jointly optimize beamforming layers and DNN layers when using the prior knowledge of the existing beamforming algorithms, which may make the model unable to obtain the optimal separation performance. In order to solve this problem, this paper employs a set of beamformers that uniformly sample the space as a learning module in the neural network, and the initial values of their coefficients are determined by the existing maximum directivity factor (DF) beamformer. Furthermore, to obtain beam representations of source signals when their directions are unknown, a cross-attention mechanism is introduced. The experimental results show that in the separation task with reverberation, the proposed method has better performance than the current state-of-the-art temporal neural beamformer filter-and-sum network (FasNet) and several mainstream multi-channel speech separation approaches in terms of scale-invariant signal-to-noise ratio (SI-SNR), perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility measure (STOI).
中文翻译:
一种用于多通道语音分离的新型神经波束形成器
语音分离是许多语音后端任务的关键,例如多说话人语音识别。近年来,在深度学习技术的发展和帮助下,许多单通道语音分离模型在弱混响环境中表现出良好的性能。然而,随着混响的存在,多通道语音分离模型仍然具有更大的优势。其中,基于深度神经网络(DNN)的波束形成器(也称为神经波束形成器)在分离质量上取得了显着的提升。当前的神经波束形成器在利用现有波束形成算法的先验知识时,无法联合优化波束形成层和DNN层,这可能使模型无法获得最佳的分离性能。为了解决这个问题,本文采用一组对空间进行均匀采样的波束形成器作为神经网络中的学习模块,其系数的初始值由现有的最大方向性因子(DF)波束形成器确定。此外,为了在方向未知时获得源信号的波束表示,引入了交叉注意机制。实验结果表明,在具有混响的分离任务中,所提出的方法比当前最先进的时间神经波束形成器滤波和求和网络(FasNet)和几种主流的多通道语音分离方法具有更好的性能。尺度不变信噪比 (SI-SNR)、语音质量感知评估 (PESQ) 和短时客观可懂度测量 (STOI)。


























 京公网安备 11010802027423号
京公网安备 11010802027423号