Mobile Networks and Applications ( IF 3.8 ) Pub Date : 2022-05-03 , DOI: 10.1007/s11036-022-01964-0 Sérgio José de Sousa 1 , Thiago Magela Rodrigues Dias 1 , Adilson Luiz Pinto 2
|
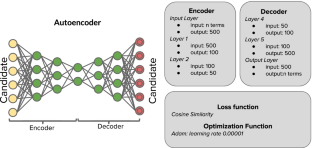
With the growing volume of data produced these days, we see more and more users using different types of systems, such as professional and scientific data storage systems. Given the large amount of stored data, the difficulty of finding candidates with appropriate profiles for a particular activity is remarkable. In this context, to try to solve this problem the retrieval or search of experts arises, a branch of information retrieval, which consists in, given a query, documents are retrieved and are related as indirect units of information of the specialties of the candidates, with this, some technique is used to aggregate these documents generating a score. Having a smaller number of related searches, the search for experts in the scientific area with neural models is an even greater challenge due to the complexity of these models and the need for large volumes of data with relevance judgments or labels for their training. Given this, this paper proposes a technique for expansion and generation of weakly supervised data where relevance judgments are created with heuristic techniques, making it possible to use models that require large volumes of data. Furthermore, a technique using deep autoencoder is proposed to select negative documents or irrelevance judgments and finally a ranking model based on recurrent networks called Dual Embedding LSTM that was able to outperform all the compared baselines.
中文翻译:
识别科学数据存储库专家的策略
随着当今数据量的不断增长,我们看到越来越多的用户使用不同类型的系统,例如专业和科学的数据存储系统。鉴于存储的大量数据,为特定活动找到具有适当配置文件的候选人的难度是显着的。在这种情况下,为了解决这个问题,专家的检索或搜索出现了,信息检索的一个分支,包括在给定查询的情况下,检索文档并将其作为候选人专业信息的间接单元相关联,有了这个,一些技术被用来聚合这些文档产生一个分数。相关搜索次数较少,由于这些模型的复杂性以及需要大量具有相关性判断或标签的数据来进行训练,因此寻找具有神经模型的科学领域的专家是一个更大的挑战。鉴于此,本文提出了一种扩展和生成弱监督数据的技术,其中通过启发式技术创建相关性判断,从而可以使用需要大量数据的模型。此外,提出了一种使用深度自动编码器的技术来选择负面文档或不相关的判断,最后提出了一种基于循环网络的排名模型,称为 Dual Embedding LSTM,它能够优于所有比较的基线。本文提出了一种扩展和生成弱监督数据的技术,其中使用启发式技术创建相关性判断,从而可以使用需要大量数据的模型。此外,提出了一种使用深度自动编码器的技术来选择负面文档或不相关的判断,最后提出了一种基于循环网络的排名模型,称为 Dual Embedding LSTM,它能够优于所有比较的基线。本文提出了一种扩展和生成弱监督数据的技术,其中使用启发式技术创建相关性判断,从而可以使用需要大量数据的模型。此外,提出了一种使用深度自动编码器的技术来选择负面文档或不相关的判断,最后提出了一种基于循环网络的排名模型,称为 Dual Embedding LSTM,它能够优于所有比较的基线。

























 京公网安备 11010802027423号
京公网安备 11010802027423号