当前位置:
X-MOL 学术
›
J. Med. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Active Learning for Drug Design: A Case Study on the Plasma Exposure of Orally Administered Drugs
Journal of Medicinal Chemistry ( IF 7.3 ) Pub Date : 2021-11-15 , DOI: 10.1021/acs.jmedchem.1c01683 Xiaoyu Ding 1, 2 , Rongrong Cui 3 , Jie Yu 1, 2 , Tiantian Liu 1, 2 , Tingfei Zhu 1, 2 , Dingyan Wang 1, 2 , Jie Chang 3 , Zisheng Fan 3 , Xiaomeng Liu 1, 2 , Kaixian Chen 1, 2, 3 , Hualiang Jiang 1, 2, 3, 4 , Xutong Li 1, 2 , Xiaomin Luo 1, 2 , Mingyue Zheng 1, 2, 3
Journal of Medicinal Chemistry ( IF 7.3 ) Pub Date : 2021-11-15 , DOI: 10.1021/acs.jmedchem.1c01683 Xiaoyu Ding 1, 2 , Rongrong Cui 3 , Jie Yu 1, 2 , Tiantian Liu 1, 2 , Tingfei Zhu 1, 2 , Dingyan Wang 1, 2 , Jie Chang 3 , Zisheng Fan 3 , Xiaomeng Liu 1, 2 , Kaixian Chen 1, 2, 3 , Hualiang Jiang 1, 2, 3, 4 , Xutong Li 1, 2 , Xiaomin Luo 1, 2 , Mingyue Zheng 1, 2, 3
Affiliation
|
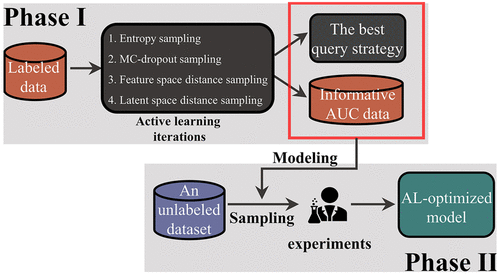
The success of artificial intelligence (AI) models has been limited by the requirement of large amounts of high-quality training data, which is just the opposite of the situation in most drug discovery pipelines. Active learning (AL) is a subfield of AI that focuses on algorithms that select the data they need to improve their models. Here, we propose a two-phase AL pipeline and apply it to the prediction of drug oral plasma exposure. In phase I, the AL-based model demonstrated a remarkable capability to sample informative data from a noisy data set, which used only 30% of the training data to yield a prediction capability with an accuracy of 0.856 on an independent test set. In phase II, the AL-based model explored a large diverse chemical space (855K samples) for experimental testing and feedback. Improved accuracy and new highly confident predictions (50K samples) were observed, which suggest that the model’s applicability domain has been significantly expanded.
中文翻译:

药物设计的主动学习:口服药物血浆暴露的案例研究
人工智能 (AI) 模型的成功受限于对大量高质量训练数据的需求,这与大多数药物发现管道的情况正好相反。主动学习 (AL) 是 AI 的一个子领域,专注于选择改进模型所需数据的算法。在这里,我们提出了一个两阶段的 AL 管道并将其应用于药物口服血浆暴露的预测。在第一阶段,基于 AL 的模型展示了从嘈杂数据集中采样信息数据的显着能力,该模型仅使用 30% 的训练数据即可在独立测试集上产生准确率为 0.856 的预测能力。在第二阶段,基于 AL 的模型探索了一个用于实验测试和反馈的大型多样化化学空间(855K 样本)。
更新日期:2021-11-25
中文翻译:
药物设计的主动学习:口服药物血浆暴露的案例研究
人工智能 (AI) 模型的成功受限于对大量高质量训练数据的需求,这与大多数药物发现管道的情况正好相反。主动学习 (AL) 是 AI 的一个子领域,专注于选择改进模型所需数据的算法。在这里,我们提出了一个两阶段的 AL 管道并将其应用于药物口服血浆暴露的预测。在第一阶段,基于 AL 的模型展示了从嘈杂数据集中采样信息数据的显着能力,该模型仅使用 30% 的训练数据即可在独立测试集上产生准确率为 0.856 的预测能力。在第二阶段,基于 AL 的模型探索了一个用于实验测试和反馈的大型多样化化学空间(855K 样本)。

























 京公网安备 11010802027423号
京公网安备 11010802027423号