Current Bioinformatics ( IF 4 ) Pub Date : 2021-05-31 , DOI: 10.2174/1574893615999210101125442 Omer Irshad 1 , Muhammad Usman Ghani Khan 1
|
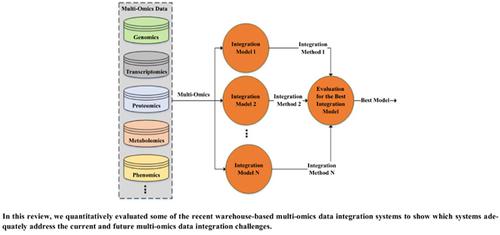
Integrating heterogeneous biological databases for unveiling the new intra-molecular and inter-molecular attributes, behaviors, and relationships in the human cellular system has always been a focused research area of computational biology. In this context, a lot of biological data integration systems have been deployed in the last couple of decades. One of the prime and common objectives of all these systems is to better facilitate the end-users for exploring, exploiting, and analyzing the integrated biological data for knowledge extraction. With the advent of especially high-throughput data generation technologies, biological data is growing and dispersing continuously, exponentially, heterogeneously, and geographically. Due to this, biological data integration systems face data integration and data organization-related current and future challenges. The objective of this review is to quantitatively evaluate and compare some of the recent warehouse- based multi-omics data integration systems to check their compliance with the current and future data integration needs. For this, we identified some of the major data integration design characteristics that should be in the multi-omics data integration model to comprehensively address the current and future data integration challenges. Based on these design characteristics and the evaluation criteria, we evaluated some of the recent data warehouse systems and showed categorical and comparative analysis results. Results show that most of the systems exhibit no or partial compliance with the required data integration design characteristics. So, these systems need design improvements to adequately address the current and future data integration challenges while keeping their service level commitments in place.
中文翻译:
以数据开发和知识发现着称的生物数据集成系统的比较分析
整合异构生物数据库以揭示人类细胞系统中新的分子内和分子间属性、行为和关系一直是计算生物学的一个重点研究领域。在这种背景下,过去几十年中已经部署了许多生物数据集成系统。所有这些系统的主要和共同目标之一是更好地促进最终用户探索、利用和分析用于知识提取的集成生物数据。随着特别是高通量数据生成技术的出现,生物数据正在不断地、指数地、异质地和地理地增长和分散。由于此,生物数据集成系统面临数据集成和数据组织相关的当前和未来挑战。本次审查的目的是定量评估和比较一些最近的基于仓库的多组学数据集成系统,以检查它们是否符合当前和未来的数据集成需求。为此,我们确定了多组学数据集成模型中应具备的一些主要数据集成设计特征,以全面应对当前和未来的数据集成挑战。基于这些设计特征和评估标准,我们评估了一些最近的数据仓库系统,并展示了分类和比较分析结果。结果表明,大多数系统不符合或部分符合所需的数据集成设计特征。因此,这些系统需要改进设计,以充分应对当前和未来的数据集成挑战,同时保持其服务水平承诺到位。


























 京公网安备 11010802027423号
京公网安备 11010802027423号