Computers & Graphics ( IF 2.5 ) Pub Date : 2021-08-08 , DOI: 10.1016/j.cag.2021.07.022 Rachel McDonnell 1 , Katja Zibrek 2 , Emma Carrigan 1 , Rozenn Dahyot 3
|
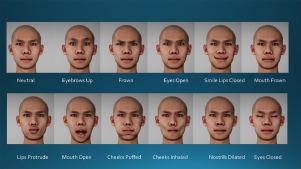
Blendshape facial rigs are used extensively in the industry for facial animation of virtual humans. However, storing and manipulating large numbers of facial meshes (blendshapes) is costly in terms of memory and computation for gaming applications. Blendshape rigs are comprised of sets of semantically-meaningful expressions, which govern how expressive the character will be, often based on Action Units from the Facial Action Coding System (FACS). However, the relative perceptual importance of blendshapes has not yet been investigated. Research in Psychology and Neuroscience has shown that our brains process faces differently than other objects so we postulate that the perception of facial expressions will be feature-dependent rather than based purely on the amount of movement required to make the expression. Therefore, we believe that perception of blendshape visibility will not be reliably predicted by numerical calculations of the difference between the expression and the neutral mesh. In this paper, we explore the noticeability of blendshapes under different activation levels, and present new perceptually-based models to predict perceptual importance of blendshapes. The models predict visibility based on commonly-used geometry and image-based metrics.
中文翻译:
使用虚拟人预测面部动作单元激活感知的模型
Blendshape 面部装备在行业中广泛用于虚拟人的面部动画。然而,就游戏应用程序的内存和计算而言,存储和操作大量面部网格(混合形状)的成本很高。Blendshape 装备由一组语义上有意义的表达式组成,这些表达式控制角色的表现力,通常基于面部动作编码系统 (FACS) 的动作单元。然而,尚未研究混合形状的相对感知重要性。心理学和神经科学的研究表明,我们的大脑处理面孔的方式与其他物体不同,因此我们假设面部表情的感知将取决于特征,而不是纯粹基于做出表情所需的运动量。所以,我们相信,通过对表达式和中性网格之间的差异进行数值计算,无法可靠地预测混合形状可见性的感知。在本文中,我们探索了混合形状在不同激活级别下的显着性,并提出了新的基于感知的模型来预测混合形状的感知重要性。这些模型基于常用的几何图形和基于图像的度量来预测可见性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号