Water Resources Management ( IF 4.3 ) Pub Date : 2021-07-20 , DOI: 10.1007/s11269-021-02908-1 Danieli Mara Ferreira 1 , Marcelo Coelho 1 , Cristovao Vicente Scapulatempo Fernandes 1 , Eloy Kaviski 1 , Daniel Henrique Marco Detzel 1
|
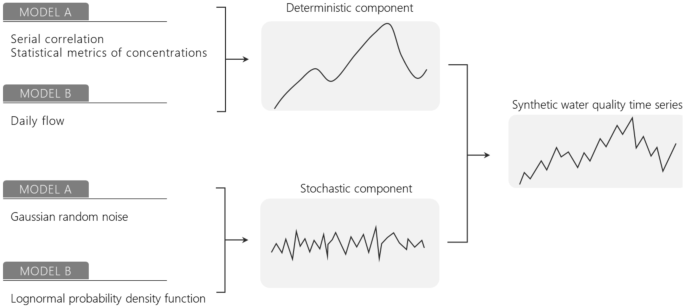
Limited water quality data is often responsible for incorrect model descriptions and misleading interpretations in terms of water resources planning and management scenarios. This study compares two hybrid strategies to convert discrete concentration data into continuous daily values for one year in distinct river sections. Model A is based on an autoregressive process, accounting for serial correlation, water quality historical characteristics (mean and standard deviation), and random variability. The second approach (model B) is a regression model based on the relationship between flow and concentrations, and an error term. The generated time series, here referred to as synthetic series, are propagated in time and space by a deterministic model (SihQual) that solves the Saint-Venant and advection-dispersion-reaction equations. The results reveal that both approaches are appropriate to reproduce the variability of biochemical oxygen demand and organic nitrogen concentrations, leading to the conclusion that the combination of deterministic/empirical and stochastic components are compatible. A second outcome arises from comparing the results for distinct time scales, supporting the need for further assessment of statistical characteristics of water quality data - which relies on monitoring strategies development. Nonetheless, the proposed methods are suitable to estimate multiple scenarios of interest for water resources planning and management.
Graphical Abstract
中文翻译:
将离散水质数据转换为连续时间序列的确定性和随机性原则
在水资源规划和管理方案方面,有限的水质数据通常是导致模型描述不正确和误导性解释的原因。本研究比较了两种混合策略,将离散浓度数据转换为不同河流断面一年的连续日值。模型 A 基于自回归过程,考虑了序列相关性、水质历史特征(平均值和标准偏差)和随机变异性。第二种方法(模型 B)是基于流量和浓度之间的关系以及误差项的回归模型。生成的时间序列(此处称为合成序列)通过确定性模型 (SihQual) 在时间和空间中传播,该模型求解圣维南方程和对流-弥散-反应方程。结果表明,这两种方法都适用于重现生化需氧量和有机氮浓度的变异性,从而得出确定性/经验性和随机性成分的组合是兼容的结论。第二个结果来自不同时间尺度的结果比较,支持进一步评估水质数据的统计特征的需要——这依赖于监测策略的制定。尽管如此,所提出的方法适用于估计水资源规划和管理的多种感兴趣的情景。得出的结论是确定性/经验和随机分量的组合是兼容的。第二个结果来自不同时间尺度的结果比较,支持进一步评估水质数据的统计特征的需要——这依赖于监测策略的制定。尽管如此,所提出的方法适用于估计水资源规划和管理的多种感兴趣的情景。得出的结论是确定性/经验和随机分量的组合是兼容的。第二个结果来自不同时间尺度的结果比较,支持进一步评估水质数据的统计特征的需要——这依赖于监测策略的制定。尽管如此,所提出的方法适用于估计水资源规划和管理的多种感兴趣的情景。

























 京公网安备 11010802027423号
京公网安备 11010802027423号