当前位置:
X-MOL 学术
›
Hum. Brain Mapp.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
The neural representation of abstract words may arise through grounding word meaning in language itself
Human Brain Mapping ( IF 4.8 ) Pub Date : 2021-07-15 , DOI: 10.1002/hbm.25593 Annika Hultén 1, 2 , Marijn van Vliet 1 , Sasa Kivisaari 1 , Lotta Lammi 1 , Tiina Lindh-Knuutila 1 , Ali Faisal 1 , Riitta Salmelin 1
Human Brain Mapping ( IF 4.8 ) Pub Date : 2021-07-15 , DOI: 10.1002/hbm.25593 Annika Hultén 1, 2 , Marijn van Vliet 1 , Sasa Kivisaari 1 , Lotta Lammi 1 , Tiina Lindh-Knuutila 1 , Ali Faisal 1 , Riitta Salmelin 1
Affiliation
|
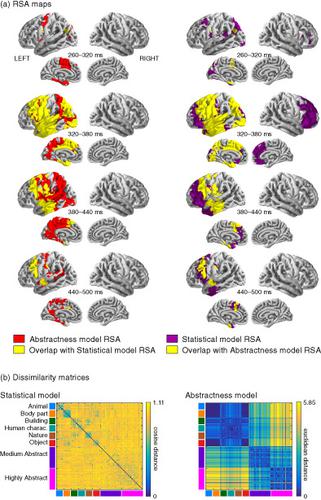
In order to describe how humans represent meaning in the brain, one must be able to account for not just concrete words but, critically, also abstract words, which lack a physical referent. Hebbian formalism and optimization are basic principles of brain function, and they provide an appealing approach for modeling word meanings based on word co-occurrences. We provide proof of concept that a statistical model of the semantic space can account for neural representations of both concrete and abstract words, using MEG. Here, we built a statistical model using word embeddings extracted from a text corpus. This statistical model was used to train a machine learning algorithm to successfully decode the MEG signals evoked by written words. In the model, word abstractness emerged from the statistical regularities of the language environment. Representational similarity analysis further showed that this salient property of the model co-varies, at 280–420 ms after visual word presentation, with activity in regions that have been previously linked with processing of abstract words, namely the left-hemisphere frontal, anterior temporal and superior parietal cortex. In light of these results, we propose that the neural encoding of word meanings can arise through statistical regularities, that is, through grounding in language itself.
中文翻译:

抽象词的神经表征可能是通过语言本身的词义基础而产生的
为了描述人类如何在大脑中表达意义,人们不仅必须能够解释具体的词,而且至关重要的是,还能够解释缺乏物理指称的抽象词。Hebbian 形式主义和优化是大脑功能的基本原理,它们为基于词共现的词义建模提供了一种有吸引力的方法。我们提供概念证明,即语义空间的统计模型可以使用 MEG 解释具体和抽象词的神经表示。在这里,我们使用从文本语料库中提取的词嵌入构建了一个统计模型。该统计模型用于训练机器学习算法,以成功解码书面文字引起的 MEG 信号。在模型中,词的抽象性来源于语言环境的统计规律。表征相似性分析进一步表明,模型的这一显着特性在视觉词呈现后 280-420 毫秒内随着之前与抽象词处理相关的区域(即左半球额叶、前颞叶)的活动而变化。和上顶叶皮层。鉴于这些结果,我们提出词义的神经编码可以通过统计规律产生,即通过语言本身的基础。
更新日期:2021-09-19
中文翻译:
抽象词的神经表征可能是通过语言本身的词义基础而产生的
为了描述人类如何在大脑中表达意义,人们不仅必须能够解释具体的词,而且至关重要的是,还能够解释缺乏物理指称的抽象词。Hebbian 形式主义和优化是大脑功能的基本原理,它们为基于词共现的词义建模提供了一种有吸引力的方法。我们提供概念证明,即语义空间的统计模型可以使用 MEG 解释具体和抽象词的神经表示。在这里,我们使用从文本语料库中提取的词嵌入构建了一个统计模型。该统计模型用于训练机器学习算法,以成功解码书面文字引起的 MEG 信号。在模型中,词的抽象性来源于语言环境的统计规律。表征相似性分析进一步表明,模型的这一显着特性在视觉词呈现后 280-420 毫秒内随着之前与抽象词处理相关的区域(即左半球额叶、前颞叶)的活动而变化。和上顶叶皮层。鉴于这些结果,我们提出词义的神经编码可以通过统计规律产生,即通过语言本身的基础。


























 京公网安备 11010802027423号
京公网安备 11010802027423号