Pattern Recognition ( IF 8 ) Pub Date : 2021-06-29 , DOI: 10.1016/j.patcog.2021.108142 Yesong Xu , Shuo Chen , Jun Li , Lei Luo , Jian Yang
|
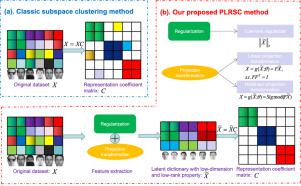
Recently, Self-Expressive-based Subspace Clustering (SESC) has been widely applied in pattern clustering and machine learning as it aims to learn a representation that can faithfully reflect the correlation between data points. However, most existing SESC methods directly use the original data as the dictionary, which miss the intrinsic structure (e.g., low-rank and nonlinear) of the real-word data. To address this problem, we propose a novel Projection Low-Rank Subspace Clustering (PLRSC) method by integrating feature extraction and subspace clustering into a unified framework. In particular, PLRSC learns a projection transformation to extract the low-dimensional features and utilizes a low-rank regularizer to ensure the informative and important structures of the extracted features. The extracted low-rank features effectively enhance the self-expressive property of the dictionary. Furthermore, we extend PLRSC to a nonlinear version (i.e., NPLRSC) by integrating a nonlinear activator into the projection transformation. NPLRSC cannot only effectively extract features but also guarantee the data structure of the extracted features. The corresponding optimization problem is solved by the Alternating Direction Method (ADM), and we also prove that the algorithm converges to a stationary point. Experimental results on the real-world datasets validate the superior of our model over the existing subspace clustering methods.
中文翻译:
用于子空间聚类的可学习低秩潜在字典
最近,基于自我表达的子空间聚类(SESC)已被广泛应用于模式聚类和机器学习,因为它旨在学习能够忠实反映数据点之间相关性的表示。然而,大多数现有的SESC方法直接使用原始数据作为字典,这遗漏了真实词数据的内在结构(例如,低秩和非线性)。为了解决这个问题,我们通过将特征提取和子空间聚类集成到一个统一的框架中,提出了一种新的投影低秩子空间聚类(PLRSC)方法。特别是,PLRSC 学习投影变换来提取低维特征,并利用低秩正则化器来确保提取特征的信息量和重要结构。提取的低秩特征有效地增强了词典的自我表达特性。此外,我们通过将非线性激活器集成到投影变换中,将 PLRSC 扩展到非线性版本(即 NPLRSC)。NPLRSC 不仅能有效提取特征,还能保证提取特征的数据结构。相应的优化问题由交替方向法(ADM)解决,我们也证明了该算法收敛到一个平稳点。真实世界数据集的实验结果验证了我们的模型优于现有子空间聚类方法。NPLRSC 不仅能有效提取特征,还能保证提取特征的数据结构。相应的优化问题由交替方向法(ADM)解决,我们也证明了该算法收敛到一个平稳点。真实世界数据集的实验结果验证了我们的模型优于现有子空间聚类方法。NPLRSC 不仅能有效提取特征,还能保证提取特征的数据结构。相应的优化问题由交替方向法(ADM)解决,我们也证明了该算法收敛到一个平稳点。真实世界数据集的实验结果验证了我们的模型优于现有子空间聚类方法。

























 京公网安备 11010802027423号
京公网安备 11010802027423号