Applied Soft Computing ( IF 8.7 ) Pub Date : 2021-05-26 , DOI: 10.1016/j.asoc.2021.107505 Zhiyang Fang , Junfeng Wang , Jiaxuan Geng , Yingjie Zhou , Xuan Kan
|
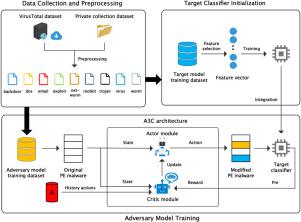
Machine learning algorithms have been proved to be vulnerable to adversarial attacks. The potential adversary is able to force the model to produce deliberate errors by elaborately modifying the training samples. For malware analysis, most of the existing research on evasion attacks focuses on a detection scenario, while less attention is paid to the classification scenario which is vital to decide a suitable system response in time. To fulfill this gap, this paper tries to address the misclassification problem in malware analysis. A reinforcement learning model named A3CMal is proposed. This adversarial model aims to generate adversarial samples which can fool the target classifier. As a core component of A3CMal, the self-learning agent constantly takes optimal actions to confuse the classification by slightly modifying samples on the basis of the observed states. Extensive experiments are performed to test the validity of A3CMal. The results show that the proposed A3CMal can force the target classifier to make wrong predictions while preserving the malicious functionality of the malware. Remarkably, not only can it cause the system to indicate an incorrect classification, but also can mislead the target model to classify malware into a specific category. Furthermore, our experiments demonstrate that the PE-based classifier is vulnerable to the adversarial samples generated by A3CMal.
中文翻译:
A3CMal:生成对抗样本以通过强化学习强制进行有针对性的错误分类
机器学习算法已被证明容易受到对抗性攻击。潜在对手能够通过精心修改训练样本来迫使模型产生故意错误。对于恶意软件分析,现有的关于规避攻击的研究大多集中在检测场景上,而较少关注对及时确定合适的系统响应至关重要的分类场景。为了弥补这一差距,本文试图解决恶意软件分析中的错误分类问题。提出了一种名为 A3CMal 的强化学习模型。该对抗模型旨在生成可以欺骗目标分类器的对抗样本。作为A3CMal的核心组件,自学习代理不断采取最佳行动,通过根据观察到的状态稍微修改样本来混淆分类。进行了大量实验以测试 A3CMal 的有效性。结果表明,所提出的 A3CMal 可以强制目标分类器做出错误的预测,同时保留恶意软件的恶意功能。值得注意的是,它不仅会导致系统指示不正确的分类,还会误导目标模型将恶意软件分类为特定类别。此外,我们的实验表明,基于 PE 的分类器容易受到 A3CMal 生成的对抗样本的影响。结果表明,所提出的 A3CMal 可以强制目标分类器做出错误的预测,同时保留恶意软件的恶意功能。值得注意的是,它不仅会导致系统指示不正确的分类,还会误导目标模型将恶意软件分类为特定类别。此外,我们的实验表明,基于 PE 的分类器容易受到 A3CMal 生成的对抗样本的影响。结果表明,所提出的 A3CMal 可以强制目标分类器做出错误的预测,同时保留恶意软件的恶意功能。值得注意的是,它不仅会导致系统指示不正确的分类,还会误导目标模型将恶意软件分类为特定类别。此外,我们的实验表明,基于 PE 的分类器容易受到 A3CMal 生成的对抗样本的影响。


























 京公网安备 11010802027423号
京公网安备 11010802027423号