当前位置:
X-MOL 学术
›
Environ. Sci. Technol. Lett.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
A Statistical Approach for Identifying Private Wells Susceptible to Perfluoroalkyl Substances (PFAS) Contamination
Environmental Science & Technology Letters ( IF 10.9 ) Pub Date : 2021-05-11 , DOI: 10.1021/acs.estlett.1c00264 Xindi C Hu 1, 2, 3 , Beverly Ge 1 , Bridger J Ruyle 1 , Jennifer Sun 1 , Elsie M Sunderland 1, 3
Environmental Science & Technology Letters ( IF 10.9 ) Pub Date : 2021-05-11 , DOI: 10.1021/acs.estlett.1c00264 Xindi C Hu 1, 2, 3 , Beverly Ge 1 , Bridger J Ruyle 1 , Jennifer Sun 1 , Elsie M Sunderland 1, 3
Affiliation
|
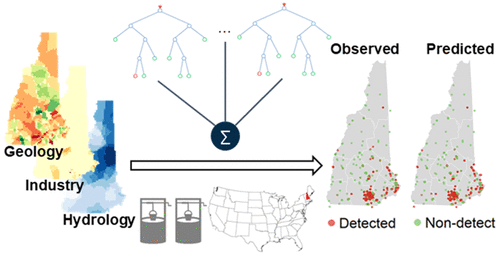
Drinking water concentrations of per- and polyfluoroalkyl substances (PFAS) exceed provisional guidelines for millions of Americans. Data on private well PFAS concentrations are limited in many regions, and monitoring initiatives are costly and time-consuming. Here, we examine modeling approaches for predicting private wells likely to have detectable PFAS concentrations that could be used to prioritize monitoring initiatives. We used nationally available data on PFAS sources, and geologic, hydrologic and soil properties that affect PFAS transport as predictors, and trained and evaluated models using PFAS data (n ∼ 2300 wells) collected by the state of New Hampshire between 2014 and 2017. Models were developed for the five most frequently detected PFAS: perfluoropentanoate, perfluorohexanoate, perfluoroheptanoate, perfluorooctanoate, and perfluorooctanesulfonate. Classification random forest models that allow nonlinearity in interactions among predictors performed the best (area under the receiver operating characteristics curve: 0.74–0.86). Point sources such as the plastics/rubber and textile industries accounted for the highest contribution to accuracy. Groundwater recharge, precipitation, soil sand content, and hydraulic conductivity were secondary predictors. Our study demonstrates the utility of machine learning models for predicting PFAS in private wells, and the classification random forest model based on nationally available predictors is readily extendable to other regions.
中文翻译:

识别易受全氟烷基物质 (PFAS) 污染的私人水井的统计方法
饮用水中全氟烷基物质和多氟烷基物质 (PFAS) 的浓度超出了数百万美国人的临时准则。许多地区有关私人油井 PFAS 浓度的数据有限,而且监测举措成本高昂且耗时。在这里,我们研究了预测私人油井可能含有可检测到的 PFAS 浓度的建模方法,这些浓度可用于确定监测举措的优先顺序。我们使用关于 PFAS 来源以及影响 PFAS 迁移的地质、水文和土壤特性的全国可用数据作为预测因子,并使用 PFAS 数据训练和评估模型(n∼ 2300 口井)由新罕布什尔州在 2014 年至 2017 年间收集。针对五种最常检测到的 PFAS 开发了模型:全氟戊酸盐、全氟己酸盐、全氟庚酸盐、全氟辛酸盐和全氟辛烷磺酸盐。允许预测变量之间相互作用呈非线性的分类随机森林模型表现最佳(接收者操作特征曲线下面积:0.74-0.86)。塑料/橡胶和纺织工业等点源对准确性的贡献最大。地下水补给、降水、土壤含沙量和导水率是次要预测因素。我们的研究证明了机器学习模型在预测私人油井中的 PFAS 方面的实用性,
更新日期:2021-07-13
中文翻译:
识别易受全氟烷基物质 (PFAS) 污染的私人水井的统计方法
饮用水中全氟烷基物质和多氟烷基物质 (PFAS) 的浓度超出了数百万美国人的临时准则。许多地区有关私人油井 PFAS 浓度的数据有限,而且监测举措成本高昂且耗时。在这里,我们研究了预测私人油井可能含有可检测到的 PFAS 浓度的建模方法,这些浓度可用于确定监测举措的优先顺序。我们使用关于 PFAS 来源以及影响 PFAS 迁移的地质、水文和土壤特性的全国可用数据作为预测因子,并使用 PFAS 数据训练和评估模型(n∼ 2300 口井)由新罕布什尔州在 2014 年至 2017 年间收集。针对五种最常检测到的 PFAS 开发了模型:全氟戊酸盐、全氟己酸盐、全氟庚酸盐、全氟辛酸盐和全氟辛烷磺酸盐。允许预测变量之间相互作用呈非线性的分类随机森林模型表现最佳(接收者操作特征曲线下面积:0.74-0.86)。塑料/橡胶和纺织工业等点源对准确性的贡献最大。地下水补给、降水、土壤含沙量和导水率是次要预测因素。我们的研究证明了机器学习模型在预测私人油井中的 PFAS 方面的实用性,


























 京公网安备 11010802027423号
京公网安备 11010802027423号