Neurocomputing ( IF 6 ) Pub Date : 2021-05-07 , DOI: 10.1016/j.neucom.2021.05.005 Zhiguang Zhou , Yuming Ma , Yong Zhang , Yanan Liu , Yuhua Liu , Lin Zhang , Shengchun Deng
|
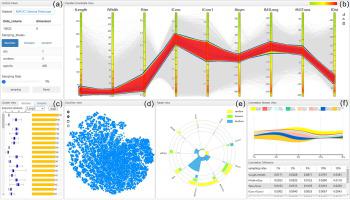
As the size of dataset increases, it has become a difficult task to explore structures of interest from crowded parallel coordinates due to visual clutter. Numerous methods have been proposed to simplify the visualization of crowded parallel coordinates, such as filtering, bundling and sampling. However, contextual structures are hardly preserved in the course of simplification, which make significant features easily lost in the simplified parallel coordinates. In this paper, we propose a context-aware visual sampling method for the exploration of crowded parallel coordinates. A Doc2Vec model, widely used in the field of Natural Language Processing (NLP), is utilized to represent the contextual structures across a series of attribute axes with quantifiable vectors. Then, an adaptive blue noise sampling model is employed to reduce the size of original dataset in the vectorized space, guarantying that data items with different contextual structures would be retained in the simplified parallel coordinates. A set of meaningful visual interfaces are designed, enabling users to easily capture the contextual features and evaluate the sampled parallel coordinates. Case studies based on real-world datasets and quantitative comparison have demonstrated the effectiveness of our method in the simplification of crowded parallel coordinates and the exploration of large scale multi-dimensional datasets.
中文翻译:
拥挤平行坐标的上下文感知视觉抽象
随着数据集大小的增加,由于视觉混乱,从拥挤的平行坐标中探索感兴趣的结构已成为一项艰巨的任务。已经提出了许多方法来简化拥挤平行坐标的可视化,例如过滤、捆绑和采样。然而,在简化过程中几乎没有保留上下文结构,这使得在简化的平行坐标中容易丢失重要特征。在本文中,我们提出了一种上下文感知的视觉采样方法,用于探索拥挤的平行坐标。Doc2Vec 模型广泛用于自然语言处理 (NLP) 领域,用于表示具有可量化向量的一系列属性轴上的上下文结构。然后,采用自适应蓝噪声采样模型来减少矢量化空间中原始数据集的大小,保证具有不同上下文结构的数据项将保留在简化的平行坐标中。设计了一组有意义的视觉界面,使用户能够轻松捕获上下文特征并评估采样的平行坐标。基于真实世界数据集和定量比较的案例研究证明了我们的方法在简化拥挤的平行坐标和探索大规模多维数据集方面的有效性。使用户能够轻松捕获上下文特征并评估采样的平行坐标。基于真实世界数据集和定量比较的案例研究证明了我们的方法在简化拥挤的平行坐标和探索大规模多维数据集方面的有效性。使用户能够轻松捕获上下文特征并评估采样的平行坐标。基于真实世界数据集和定量比较的案例研究证明了我们的方法在简化拥挤的平行坐标和探索大规模多维数据集方面的有效性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号