Ore Geology Reviews ( IF 3.3 ) Pub Date : 2021-04-30 , DOI: 10.1016/j.oregeorev.2021.104200 Majigsuren Enkhsaikhan , Eun-Jung Holden , Paul Duuring , Wei Liu
|
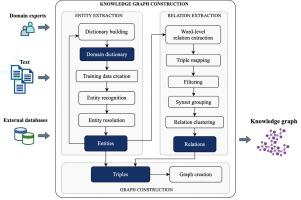
Mineral exploration reports assist present day exploration by providing valuable observations about the geological environments in which mineral deposits form. Querying and aggregating historical data can assist in reducing future exploration risks and costs. However, since the reports are written in unstructured text, it is a challenging task to derive meaningful geological information without manually reading through a large collection of reports, which is a formidable task for geologists. In this study, geological information relevant to mineralisation and ore-forming conditions is automatically extracted from such under-utilised exploration reports. This is achieved by constructing knowledge graphs that describe geological entities and their relations as they appear in exploration reports. Natural language processing and deep learning methods are used to automatically extract and label geological terms with the correct entity types and establish the relationships between these entities. In this research, six dominant entity types are considered, namely, geographical location, geological timescale, stratigraphic unit, rock type, ore and deposit type, and contained minerals. Two knowledge graphs are constructed for two high-quality mineral exploration reports, one for iron ore and the other for gold deposit, to illustrate the effectiveness of our methodology. The knowledge graphs are then assessed by determining whether the contents of the source reports were depicted accurately, specifically the labelled geological terms in the nodes and their associations in node connections. The results show that the structured information stored in the knowledge graphs faithfully represent the contents of the source reports, matching well with the domain knowledge. The proposed methods are capable of rapidly and robustly transforming text data into a structured form, the untapped area towards geological knowledge mining.
中文翻译:
使用机器阅读文本了解成矿条件
矿物勘探报告通过提供有关形成矿床的地质环境的有价值的观察,来协助当今的勘探。查询和汇总历史数据可以帮助降低未来的勘探风险和成本。但是,由于报告是以非结构化文本编写的,因此在不手动读取大量报告的情况下获得有意义的地质信息是一项艰巨的任务,这对地质学家而言是一项艰巨的任务。在这项研究中,与矿化和成矿条件有关的地质信息是从未充分利用的勘探报告中自动提取的。这是通过构建描述地质实体及其在勘探报告中出现的关系的知识图来实现的。自然语言处理和深度学习方法用于自动提取和标记具有正确实体类型的地质术语,并建立这些实体之间的关系。在这项研究中,考虑了六种主要实体类型,即地理位置,地质时标,地层单位,岩石类型,矿石和矿床类型以及所含矿物。为两个高质量的矿产勘探报告构建了两个知识图,一个用于铁矿石,另一个用于金矿,以说明我们的方法的有效性。然后,通过确定是否准确地描述了源报告的内容(尤其是节点中标记的地质术语及其在节点连接中的关联)来评估知识图。结果表明,存储在知识图中的结构化信息忠实地代表了源报告的内容,与领域知识很好地匹配。所提出的方法能够将文本数据快速而稳健地转换为结构化形式,即未开发的区域,用于地质知识挖掘。

























 京公网安备 11010802027423号
京公网安备 11010802027423号