Computers & Graphics ( IF 2.5 ) Pub Date : 2021-04-23 , DOI: 10.1016/j.cag.2021.04.018 Lu Zou , Zhangjin Huang , Fangjun Wang , Zhouwang Yang , Guoping Wang
|
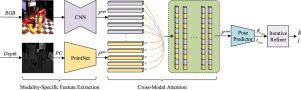
Deep learning methods for 6D object pose estimation based on RGB and depth (RGB-D) images have been successfully applied to robotic manipulation and grasping. Among these approaches, the fusion of RGB and depth modalities is one of the most critical issues. Most existing works performed fusion via either simple concatenation, or element-wise multiplication of the features generated by these two modalities. Despite achieving impressive progress, such fusion strategies do not explicitly consider the different contributions of RGB and depth modalities, leaving a gap for performance enhancement. In this paper, we present a Cross-Modal Attention (CMA) component for the problem of 6D object pose estimation. With the attention mechanism, features of two different modalities are aggregated adaptively through the attention weights, such that powerful representations from the RGB-D images can be efficiently extracted. Comprehensive experiments on both LINEMOD and YCB-Video datasets demonstrate that the proposed approach achieves state-of-the-art performance.
中文翻译:
CMA:6D对象姿态估计的跨模态注意
基于RGB和深度(RGB-D)图像的6D对象姿态估计的深度学习方法已成功应用于机器人操纵和抓取。在这些方法中,RGB和深度模态的融合是最关键的问题之一。现有的大多数工作都是通过简单的串联或这两种模态生成的特征的逐元素乘法来进行融合的。尽管取得了令人瞩目的进步,但这种融合策略并未明确考虑RGB和深度模态的不同贡献,从而在性能提升方面存在差距。在本文中,我们针对6D对象姿态估计问题提出了一种跨模态注意(CMA)组件。通过注意力机制,可以通过注意力权重自适应地聚合两种不同模式的特征,这样就可以有效地提取RGB-D图像的强大表现力。在LINEMOD和YCB-Video数据集上进行的综合实验表明,所提出的方法可实现最先进的性能。

























 京公网安备 11010802027423号
京公网安备 11010802027423号