Computers & Graphics ( IF 2.5 ) Pub Date : 2021-04-19 , DOI: 10.1016/j.cag.2021.04.003 Jiancheng Ni , Susu Zhang , Zili Zhou , Lijun Hou , Jie Hou , Feng Gao
|
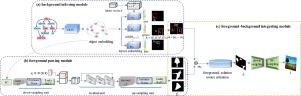
Despite recent generative models have made remarkable progress on adversarial image synthesis, it is still a pivotal and frontier problem to generate high-fidelity images containing diverse entities and complex scene layouts from structured descriptions. To this end, we present a Background and Foreground Disentangled Generative Adversarial Network (BFD-GAN) to synthesize high-quality images from scene graphs. First, our method uses the graph convolutional network to infer a semantic background from the input scene graph. Then, the foreground parsing module that encourages unsupervised generation, is proposed to calculate semantically related foregrounds with fine-grained geometric properties. Furthermore, we also employ the foreground-background integrating module for the final image generation, during which the foreground-relation aware attention is introduced to refine and fuse the inferred foregrounds into the background. Evaluated on the COCO-Stuff and Visual Genome datasets, we benchmark our model against existing methods and show that our BFD-GAN is more capable of generating complex backgrounds and corresponding sharp foregrounds with given scene structures.
中文翻译:
用于场景图像合成的背景和前景解开生成对抗网络
尽管最近的生成模型在对抗图像合成方面取得了显着进展,但是从结构化描述中生成包含不同实体和复杂场景布局的高保真图像仍然是一个关键而前沿的问题。为此,我们提出了背景和前景非纠缠生成对抗网络(BFD-GAN),以从场景图中合成高质量图像。首先,我们的方法使用图卷积网络从输入场景图推断语义背景。然后,提出了鼓励无监督生成的前景分析模块,以计算具有细粒度几何特性的语义相关前景。此外,我们还采用了前景背景整合模块来生成最终图像,在此期间,引入了与前景相关的注意,以将推断出的前景细化并融合到背景中。通过对COCO-Stuff和Visual Genome数据集进行评估,我们对照现有方法对模型进行了基准测试,结果表明,在给定的场景结构下,我们的BFD-GAN更能够生成复杂的背景和相应的清晰前景。


























 京公网安备 11010802027423号
京公网安备 11010802027423号