Information Systems ( IF 3.7 ) Pub Date : 2021-04-08 , DOI: 10.1016/j.is.2021.101774 Matej Antol , Jaroslav Ol’ha , Terézia Slanináková , Vlastislav Dohnal
|
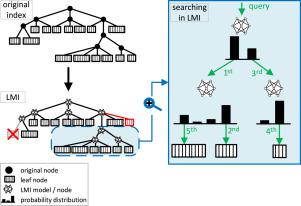
The main paradigm of similarity searching in metric spaces has remained mostly unchanged for decades — data objects are organized into a hierarchical structure according to their mutual distances, using representative pivots to reduce the number of distance computations needed to efficiently search the data. We propose an alternative to this paradigm, using machine learning models to replace pivots, thus posing similarity search as a classification problem, which stands in for numerous expensive distance computations. Even a relatively naïve implementation of this idea is more than competitive with state-of-the-art methods in terms of speed and recall, proving the concept as viable and showing great potential for its future development.
中文翻译:
Learned Metric Index(学习的指标索引)—针对非结构化数据的学习索引的建议
度量空间中相似性搜索的主要范例几十年来一直保持不变-数据对象根据它们之间的相互距离被组织为分层结构,使用代表性的枢轴来减少有效搜索数据所需的距离计算数量。我们提出了一种替代此范例的方法,使用机器学习模型代替枢轴,从而将相似性搜索作为分类问题,这代表着众多昂贵的距离计算。就速度和召回性而言,即使是相对简单的实施该想法也不能与最新方法相抗衡,证明了该概念是可行的,并显示出其未来发展的巨大潜力。
























 京公网安备 11010802027423号
京公网安备 11010802027423号