European Journal of Agronomy ( IF 5.2 ) Pub Date : 2021-03-16 , DOI: 10.1016/j.eja.2021.126276 Jonathan J. Ojeda , Ehsan Eyshi Rezaei , Tomas A. Remenyi , Heidi A. Webber , Stefan Siebert , Holger Meinke , Mathew A. Webb , Bahareh Kamali , Rebecca M.B. Harris , Darren B. Kidd , Caroline L. Mohammed , John McPhee , Jose Capuano , Frank Ewert
|
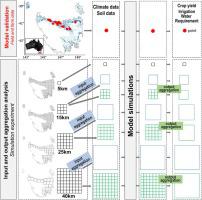
Crop models were originally developed for application at the field scale but are increasingly used to assess the impact of climate and/or agronomic practices on crop growth and yield and water dynamics at larger scales. This raises the question of how data aggregation approaches affect outputs when using crop models at large spatial scales. This study investigates how input and output data aggregation affected simulated rainfed and irrigated potato yield and irrigation water requirement (IWR) across potato production areas in Tasmania, Australia. First, the yield and IWR with aggregated model inputs at 15, 25 and 40 km resolutions (input aggregation) was simulated. Second, simulated model outputs generated with high-resolution input data were aggregated to 15, 25 and 40 km resolutions (output aggregation) and compared to the corresponding yield and IWR with simulations based on input data aggregation. Finally, the differences () ( and for yield and IWR, respectively) between grids using input and output aggregation were evaluated. The results indicate that the effect of input and output data aggregation on yield depends on water-driven factors including plant available water capacity (PAWC), rainfall and irrigation. Maximum values were found for rainfed yield (4.4 t ha−1) and IWR (137 mm). variations were correlated with the differences of PAWC caused by data aggregation in 82 % of potato production areas. Differences between aggregation methods were reduced when growing season rainfall increased. We conclude that PAWC and the source of water (rainfall or rainfall + irrigation) explained the larger errors associated with the input and output data aggregation on simulated potato yield and IWR. Future studies should consider the data aggregation method in their assessment to minimize errors and therefore produce higher quality advice or farming decisions.
中文翻译:
数据汇总方法对农作物模型产量的影响–以澳大利亚塔斯马尼亚州的灌溉马铃薯系统为例
作物模型最初是为在田间规模上应用而开发的,但现在越来越多地用于评估气候和/或农学实践对作物生长,产量和水分动态的影响。这就提出了一个问题,即在大空间尺度上使用作物模型时,数据聚合方法如何影响输出。这项研究调查了输入和输出数据汇总如何影响澳大利亚塔斯马尼亚州马铃薯生产区的模拟雨养和灌溉马铃薯产量和灌溉需水量(IWR)。首先,模拟了在15、25和40 km分辨率下的模型输入(输入聚合)下的收益率和IWR。其次,将高分辨率输入数据生成的模拟模型输出汇总为15,25和40 km的分辨率(输出聚合),并与基于基于输入数据聚合的模拟的相应产量和IWR进行了比较。最后,差异()( 和 分别使用输入和输出聚合对网格之间的产量和IWR进行了评估。结果表明,输入和输出数据汇总对产量的影响取决于水驱动因素,包括植物可用水量(PAWC),降雨和灌溉。最大雨养产量(4.4 t ha -1)和IWR(137 mm)被发现。差异与82%马铃薯产区数据聚集引起的PAWC差异相关。随着生长期降雨增加,聚集方法之间的差异减小。我们得出的结论是,PAWC和水源(降雨或降雨+灌溉)解释了与模拟马铃薯产量和IWR的输入和输出数据聚合相关的较大误差。未来的研究应在评估中考虑数据汇总方法,以最大程度地减少错误,从而提供更高质量的建议或种植决策。

























 京公网安备 11010802027423号
京公网安备 11010802027423号