当前位置:
X-MOL 学术
›
Drug Test. Anal.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Towards compound identification of synthetic opioids in nontargeted screening using machine learning techniques
Drug Testing and Analysis ( IF 2.9 ) Pub Date : 2020-11-18 , DOI: 10.1002/dta.2976 Joshua Klingberg 1 , Adam Cawley 2 , Ronald Shimmon 1 , Shanlin Fu 1
Drug Testing and Analysis ( IF 2.9 ) Pub Date : 2020-11-18 , DOI: 10.1002/dta.2976 Joshua Klingberg 1 , Adam Cawley 2 , Ronald Shimmon 1 , Shanlin Fu 1
Affiliation
|
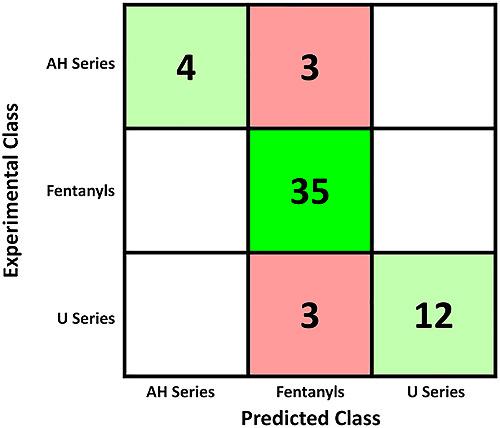
The constant evolution of the illicit drug market makes the identification of unknown compounds problematic. Obtaining certified reference materials for a broad array of new analogues can be difficult and cost prohibitive. Machine learning provides a promising avenue to putatively identify a compound before confirmation against a standard. In this study, machine learning approaches were used to develop class prediction and retention time prediction models. The developed class prediction model used a naïve Bayes architecture to classify opioids as belonging to either the fentanyl analogues, AH series or U series, with an accuracy of 89.5%. The model was most accurate for the fentanyl analogues, most likely due to their greater number in the training data. This classification model can provide guidance to an analyst when determining a suspected structure. A retention time prediction model was also trained for a wide array of synthetic opioids. This model utilised Gaussian process regression to predict the retention time of analytes based on multiple generated molecular features with 79.7% of the samples predicted within ±0.1 min of their experimental retention time. Once the suspected structure of an unknown compound is determined, molecular features can be generated and input for the prediction model to compare with experimental retention time. The incorporation of machine learning prediction models into a compound identification workflow can assist putative identifications with greater confidence and ultimately save time and money in the purchase and/or production of superfluous certified reference materials.
中文翻译:

使用机器学习技术在非靶向筛选中对合成阿片类药物进行化合物鉴定
非法药物市场的不断发展使未知化合物的鉴定成为问题。获得大量新类似物的认证参考材料可能很困难,而且成本高昂。机器学习提供了一种有前途的途径,可以在根据标准进行确认之前推测性地识别化合物。在这项研究中,机器学习方法被用于开发类别预测和保留时间预测模型。开发的类别预测模型使用朴素贝叶斯架构将阿片类药物分类为芬太尼类似物、AH 系列或 U 系列,准确率为 89.5%。该模型对于芬太尼类似物最准确,很可能是因为它们在训练数据中的数量更多。该分类模型可以在确定可疑结构时为分析人员提供指导。还针对多种合成阿片类药物训练了保留时间预测模型。该模型利用高斯过程回归根据多个生成的分子特征预测分析物的保留时间,其中 79.7% 的样品预测在其实验保留时间的 ±0.1 分钟内。一旦确定了未知化合物的可疑结构,就可以生成分子特征并将其输入到预测模型中,以与实验保留时间进行比较。
更新日期:2020-11-18
中文翻译:
使用机器学习技术在非靶向筛选中对合成阿片类药物进行化合物鉴定
非法药物市场的不断发展使未知化合物的鉴定成为问题。获得大量新类似物的认证参考材料可能很困难,而且成本高昂。机器学习提供了一种有前途的途径,可以在根据标准进行确认之前推测性地识别化合物。在这项研究中,机器学习方法被用于开发类别预测和保留时间预测模型。开发的类别预测模型使用朴素贝叶斯架构将阿片类药物分类为芬太尼类似物、AH 系列或 U 系列,准确率为 89.5%。该模型对于芬太尼类似物最准确,很可能是因为它们在训练数据中的数量更多。该分类模型可以在确定可疑结构时为分析人员提供指导。还针对多种合成阿片类药物训练了保留时间预测模型。该模型利用高斯过程回归根据多个生成的分子特征预测分析物的保留时间,其中 79.7% 的样品预测在其实验保留时间的 ±0.1 分钟内。一旦确定了未知化合物的可疑结构,就可以生成分子特征并将其输入到预测模型中,以与实验保留时间进行比较。


























 京公网安备 11010802027423号
京公网安备 11010802027423号