Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-11-19 , DOI: 10.1016/j.jbi.2020.103625 Stefan Bruch 1 , Lisa Ernst 1 , Mareike Schulz 1 , Leonie Zieglowski 1 , René H Tolba 1
|
Objective:
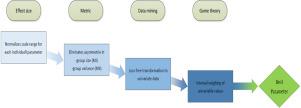
To develop and evaluate methods to assess single and grouped variables impact on measuring intervention severities and support a search for most expressive variables.
Methods:
Datasets of cohort studies are analyzed automatically based on algorithms. For this, a metric is developed to compare measured variables in different cohorts in a data-mining process. Variables are measured in all possible combinations to detect possible synergies of certain variable constellations and allow for a ranking of the combinations’ expressiveness. Such ranking serves as a basis for a wide range of algorithmic data analysis. In an exemplary application, every group member’s impact on the total result is determined based on the principle of the cooperative game theory besides to the total expressiveness of the variable groups.
Results:
For different types of interventions, the method is applied to experimental data containing multiple recorded medical lab values. The expressiveness of variable combinations to indicate severity is ranked by means of a metric. Within each combination, any variable’s contribution to the total effect is determined and accumulated over whole datasets to yield local and global variable importance measures. The computed results have been successfully matched with clinical expectations to prove their plausibility.
Conclusion:
Algorithmic evaluation shows to be a promising approach in automatized quantification of variable expressiveness. It can assess descriptive power of measurements, help to improve future study designs and expose worthwhile research issues.
中文翻译:
通过数据挖掘和合作博弈理论进行最佳变量识别
目的:
开发和评估评估单个变量和分组变量对测量干预严重程度的影响并支持搜索最具表现力的变量的方法。
方法:
队列研究的数据集会根据算法自动进行分析。为此,开发了一种度量标准以比较数据挖掘过程中不同队列中的测量变量。在所有可能的组合中测量变量,以检测某些变量星座的可能协同作用,并允许对组合的表现力进行排名。这样的排名是各种算法数据分析的基础。在示例性应用中,除了变量组的总表达能力之外,还基于合作博弈原理确定每个组成员对总结果的影响。
结果:
对于不同类型的干预措施,该方法适用于包含多个记录的医学实验室值的实验数据。通过度量对表示严重性的变量组合的表示性进行排名。在每个组合中,确定任何变量对总效果的贡献并在整个数据集上进行累积,以产生局部和全局变量重要性度量。计算结果已与临床预期成功匹配,证明了其合理性。
结论:
算法评估显示了在变量表达的自动化量化中的一种有前途的方法。它可以评估测量的描述能力,帮助改进未来的研究设计并揭示有价值的研究问题。

























 京公网安备 11010802027423号
京公网安备 11010802027423号