Geoscience Frontiers ( IF 8.9 ) Pub Date : 2020-11-18 , DOI: 10.1016/j.gsf.2020.10.005 Jordan J. Lindsay , Hannah S.R. Hughes , Christopher M. Yeomans , Jens C.Ø. Andersen , Iain McDonald
|
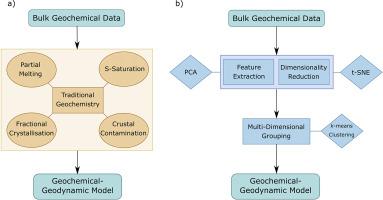
Whilst traditional approaches to geochemistry provide valuable insights into magmatic processes such as melting and element fractionation, by considering entire regional data sets on an objective basis using machine learning algorithms (MLA), we can highlight new facets within the broader data structure and significantly enhance previous geochemical interpretations. The platinum-group element (PGE) budget of lavas in the North Atlantic Igneous Province (NAIP) have been shown to vary systematically according to age, geographic location and geodynamic environment. Given the large multi-element geochemical data set available for the region, MLA was employed to explore the magmatic controls on these shifting concentrations. The key advantage of using machine learning in analysis is its ability to cluster samples across multi-dimensional (i.e., multi-element) space. The NAIP data set is manipulated using Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbour Embedding (t-SNE) techniques to increase separability in the data alongside clustering using the k-means MLA. The new multi-element classification is compared to the original geographic classification to assess the performance of both approaches. The workflow provides a means for creating an objective high-dimensional investigation on a geochemical data set and particularly enhances the identification of metallogenic anomalies across the region. The techniques used highlight three distinct multi-element end-members which successfully capture the variability of the majority of elements included as input variables. These end-members are seen to fluctuate in prominence throughout the NAIP, which we propose reflects the changing geodynamic environment and melting source. Crucially, the variability of Pt and Pd are not reflected in MLA-based clustering trends, suggesting that they vary independently through controls not readily demonstrated by the NAIP major or trace element data structure (i.e., other proxies for magmatic differentiation). This data science approach thus highlights that PGE (here signalled by Pt/Pd ratio) may be used to identify otherwise localised or cryptic geochemical inputs from the subcontinental lithospheric mantle (SCLM) during the ascent of plume-derived magma, and thereby impact upon the resulting metallogenic basket.
中文翻译:
一种用于区域地球化学数据的机器学习方法:北大西洋火成岩省的铂族元素地球化学与地球动力学设置
尽管传统的地球化学方法提供了对岩浆作用过程(如熔融和元素分馏)的宝贵见解,但通过使用机器学习算法(MLA)客观地考虑了整个区域数据集,我们可以在更广泛的数据结构中突出显示新的方面并显着增强以前的方法地球化学解释。研究表明,北大西洋火成岩省(NAIP)熔岩的铂族元素(PGE)预算会根据年龄,地理位置和地球动力学环境而系统地变化。鉴于该地区有大量的多元素地球化学数据集,MLA被用于探索这些变化浓度的岩浆控制。在分析中使用机器学习的主要优势在于它能够跨多个维度对样本进行聚类(例如,多元素)空间。使用主成分分析(PCA)和t分布随机邻居嵌入(t-SNE)技术处理NAIP数据集,以提高数据的可分离性,同时使用ķ-表示MLA。将新的多元素分类与原始地理分类进行比较,以评估两种方法的性能。该工作流提供了一种手段,可以对地球化学数据集进行客观的高维调查,尤其可以增强整个区域成矿异常的识别。使用的技术突出显示了三个不同的多元素最终成员,它们成功地捕获了作为输入变量包括的大多数元素的可变性。在整个NAIP中,这些末端成员的突出性会发生波动,我们建议这反映了不断变化的地球动力学环境和融化源。至关重要的是,Pt和Pd的变异性未反映在基于MLA的聚类趋势中,这表明它们通过NAIP专业或痕量元素数据结构(即,岩浆分化的其他代理)不容易证明的控制而独立变化。因此,这种数据科学方法强调了PGE(此处以Pt / Pd比表示)可用于识别羽状岩浆上升期间来自陆下岩石圈地幔(SCLM)的其他局部或隐秘地球化学输入,从而对岩浆产生影响。产生的成矿篮。

























 京公网安备 11010802027423号
京公网安备 11010802027423号