当前位置:
X-MOL 学术
›
Phys. Rev. Phys. Educ. Res.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Using machine learning to identify the most at-risk students in physics classes
Physical Review Physics Education Research ( IF 3.1 ) Pub Date : 2020-10-28 , DOI: 10.1103/physrevphyseducres.16.020130 Jie Yang , Seth DeVore , Dona Hewagallage , Paul Miller , Qing X. Ryan , John Stewart
Physical Review Physics Education Research ( IF 3.1 ) Pub Date : 2020-10-28 , DOI: 10.1103/physrevphyseducres.16.020130 Jie Yang , Seth DeVore , Dona Hewagallage , Paul Miller , Qing X. Ryan , John Stewart
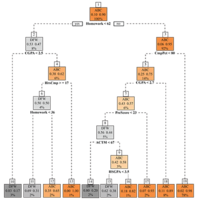
|
Machine learning algorithms have recently been used to predict students’ performance in an introductory physics class. The prediction model classified students as those likely to receive an A or B or students likely to receive a grade of C, D, F or withdraw from the class. Early prediction could better allow the direction of educational interventions and the allocation of educational resources. However, the performance metrics used in that study become unreliable when used to classify whether a student would receive an A, B, or C (the ABC outcome) or if they would receive a D, F or withdraw (W) from the class (the DFW outcome) because the outcome is substantially unbalanced with between 10% to 20% of the students receiving a D, F, or W. This work presents techniques to adjust the prediction models and alternate model performance metrics more appropriate for unbalanced outcome variables. These techniques were applied to three samples drawn from introductory mechanics classes at two institutions (, 1683, and 926). Applying the same methods as the earlier study produced a classifier that was very inaccurate, classifying only 16% of the DFW cases correctly; tuning the model increased the DFW classification accuracy to 43%. Using a combination of institutional and in-class data improved DFW accuracy to 53% by the second week of class. As in the prior study, demographic variables such as gender, underrepresented minority status, first-generation college student status, and low socioeconomic status were not important variables in the final prediction models.
中文翻译:

使用机器学习识别物理课中最危险的学生
机器学习算法最近已用于预测物理入门课中的学生表现。预测模型将学生分类为可能获得A或B成绩的学生,或可能获得C,D,F等级或退出班级的学生。早期预测可以更好地指导教育干预措施的发展和教育资源的分配。但是,用于对学生是否将获得A,B或C(ABC成绩)进行分类,还是将学生从班级中获得D,F或退学(W)时,该研究中使用的绩效指标变得不可靠( DFW结果),因为该结果基本上是不平衡的,接受D,F或W的学生中有10%至20%。这项工作提出了调整预测模型和更适合于不平衡结果变量的替代模型性能指标的技术。这些技术已应用于两个机构的基础力学课程的三个样本中(,1683和926)。采用与早期研究相同的方法,得出的分类器非常不准确,仅对DFW案例中的16%进行了正确分类。调整模型可以将DFW分类的准确性提高到43%。结合使用机构数据和课堂数据,到课堂第二周时,DFW准确性提高到53%。与先前的研究一样,人口统计学变量,如性别,少数群体地位不足,第一代大学生地位和低社会经济地位,在最终的预测模型中并不是重要的变量。
更新日期:2020-10-30
中文翻译:
使用机器学习识别物理课中最危险的学生
机器学习算法最近已用于预测物理入门课中的学生表现。预测模型将学生分类为可能获得A或B成绩的学生,或可能获得C,D,F等级或退出班级的学生。早期预测可以更好地指导教育干预措施的发展和教育资源的分配。但是,用于对学生是否将获得A,B或C(ABC成绩)进行分类,还是将学生从班级中获得D,F或退学(W)时,该研究中使用的绩效指标变得不可靠( DFW结果),因为该结果基本上是不平衡的,接受D,F或W的学生中有10%至20%。这项工作提出了调整预测模型和更适合于不平衡结果变量的替代模型性能指标的技术。这些技术已应用于两个机构的基础力学课程的三个样本中(,1683和926)。采用与早期研究相同的方法,得出的分类器非常不准确,仅对DFW案例中的16%进行了正确分类。调整模型可以将DFW分类的准确性提高到43%。结合使用机构数据和课堂数据,到课堂第二周时,DFW准确性提高到53%。与先前的研究一样,人口统计学变量,如性别,少数群体地位不足,第一代大学生地位和低社会经济地位,在最终的预测模型中并不是重要的变量。
























 京公网安备 11010802027423号
京公网安备 11010802027423号