Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-10-13 , DOI: 10.1016/j.jbi.2020.103578 Ashwin Karthik Ambalavanan 1 , Murthy V Devarakonda 1
|
Background
Finding specific scientific articles in a large collection is an important natural language processing challenge in the biomedical domain. Systematic reviews and interactive article search are the type of downstream applications that benefit from addressing this problem. The task often involves screening articles for a combination of selection criteria. While machine learning was previously used for this purpose, it is not known if different criteria should be modeled together or separately in an ensemble model. The performance impact of the modern contextual language models on the task is also not known.
Methods
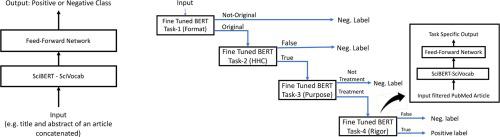
We framed the problem as text classification and conducted experiments to compare ensemble architectures, where the selection criteria were mapped to the components of the ensemble. We proposed a novel cascade ensemble analogous to the step-wise screening process employed in developing the gold standard. We compared performance of the ensembles with a single integrated model, which we refer to as the individual task learner (ITL). We used SciBERT, a variant of BERT pre-trained on scientific articles, and conducted experiments using a manually annotated dataset of ~49 K MEDLINE abstracts, known as Clinical Hedges.
Results
The cascade ensemble had significantly higher precision (0.663 vs. 0.388 vs. 0.478 vs. 0.320) and F measure (0.753 vs. 0.553 vs. 0.628 vs. 0.477) than ITL and ensembles using Boolean logic and a feed-forward network. However, ITL had significantly higher recall than the other classifiers (0.965 vs. 0.872 vs. 0.917 vs. 0.944). In fixed high recall studies, ITL achieved 0.509 precision @ 0.970 recall and 0.381 precision @ 0.985 recall on a subset that was studied earlier, and 0.295 precision @ 0.985 recall on the full dataset, all of which were improvements over the previous studies.
Conclusion
Pre-trained neural contextual language models (e.g. SciBERT) performed well for screening scientific articles. Performance at high fixed recall makes the single integrated model (ITL) more suitable among the architectures considered here, for systematic reviews. However, high F measure of the cascade ensemble makes it a better approach for interactive search applications. The effectiveness of the cascade ensemble architecture suggests broader applicability beyond this task and the dataset, and the approach is analogous to query optimization in Information Retrieval and query optimization in databases.
中文翻译:
使用上下文语言模型BERT进行科学论文的多标准分类
背景
在大量医学文献中寻找特定的科学文章是生物医学领域重要的自然语言处理挑战。系统评价和交互式文章搜索是受益于解决此问题的下游应用程序的类型。该任务通常涉及筛选商品以选择标准的组合。虽然以前将机器学习用于此目的,但尚不清楚应将不同的准则一起建模还是在集成模型中分别建模。现代上下文语言模型对任务的性能影响也是未知的。
方法
我们将该问题归类为文本分类,并进行了实验以比较集合体系结构,其中选择标准映射到集合的组件。我们提出了一种新颖的级联合奏,类似于开发金标准的逐步筛选过程。我们将集成的性能与单个集成模型进行了比较,我们将其称为单个任务学习者(ITL)。我们使用SciBERT,它是在科学文章中经过预训练的BERT的变体,并使用〜49 K MEDLINE摘要的手动注释数据集(称为临床对冲)进行了实验。
结果
与ITL相比,级联乐团的精度(0.663 vs. 0.388 vs. 0.478 vs. 0.320)和F度量(0.753 vs. 0.553 vs. 0.628 vs. 0.477)具有更高的精度,并且使用布尔逻辑和前馈网络进行合奏。但是,ITL的召回率明显高于其他分类器(0.965 vs. 0.872 vs. 0.917 vs. 0.944)。在固定的高召回率研究中,ITL在较早研究的子集上实现了0.509精度@ 0.970召回率和0.381精度@ 0.985召回率,以及整个数据集的0.295精度@ 0.985召回率,所有这些都是对先前研究的改进。
结论
预先训练的神经环境语言模型(例如SciBERT)在筛选科学文章方面表现良好。较高的固定召回率下的性能使单个集成模型(ITL)更适合此处考虑的体系结构,以进行系统评估。但是,级联集成的高F度量使其成为交互式搜索应用程序的更好方法。级联集成体系结构的有效性表明,除了此任务和数据集之外,它还具有更广泛的适用性,并且该方法类似于信息检索中的查询优化和数据库中的查询优化。

























 京公网安备 11010802027423号
京公网安备 11010802027423号