当前位置:
X-MOL 学术
›
Phys. Rev. E
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Statistical learning theory of structured data
Physical Review E ( IF 2.4 ) Pub Date : 2020-09-14 , DOI: 10.1103/physreve.102.032119 Mauro Pastore , Pietro Rotondo , Vittorio Erba , Marco Gherardi
Physical Review E ( IF 2.4 ) Pub Date : 2020-09-14 , DOI: 10.1103/physreve.102.032119 Mauro Pastore , Pietro Rotondo , Vittorio Erba , Marco Gherardi
|
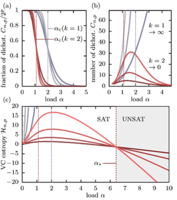
The traditional approach of statistical physics to supervised learning routinely assumes unrealistic generative models for the data: Usually inputs are independent random variables, uncorrelated with their labels. Only recently, statistical physicists started to explore more complex forms of data, such as equally labeled points lying on (possibly low-dimensional) object manifolds. Here we provide a bridge between this recently established research area and the framework of statistical learning theory, a branch of mathematics devoted to inference in machine learning. The overarching motivation is the inadequacy of the classic rigorous results in explaining the remarkable generalization properties of deep learning. We propose a way to integrate physical models of data into statistical learning theory and address, with both combinatorial and statistical mechanics methods, the computation of the Vapnik-Chervonenkis entropy, which counts the number of different binary classifications compatible with the loss class. As a proof of concept, we focus on kernel machines and on two simple realizations of data structure introduced in recent physics literature: -dimensional simplexes with prescribed geometric relations and spherical manifolds (equivalent to margin classification). Entropy, contrary to what happens for unstructured data, is nonmonotonic in the sample size, in contrast with the rigorous bounds. Moreover, data structure induces a transition beyond the storage capacity, which we advocate as a proxy of the nonmonotonicity, and ultimately a cue of low generalization error. The identification of a synaptic volume vanishing at the transition allows a quantification of the impact of data structure within replica theory, applicable in cases where combinatorial methods are not available, as we demonstrate for margin learning.
中文翻译:

结构化数据的统计学习理论
统计物理学用于监督学习的传统方法通常假定数据的生成模型不切实际:通常,输入是独立的随机变量,与它们的标签无关。直到最近,统计物理学家才开始探索更复杂的数据形式,例如位于(可能是低维的)物体流形上的同样标记的点。在这里,我们提供了这个最近建立的研究领域与统计学习理论框架之间的桥梁,统计学习理论是专门用于机器学习推理的数学分支。总的动机是经典的严格结果不足以解释深度学习的显着概括特性。我们提出了一种将数据的物理模型集成到统计学习理论和地址中的方法,使用组合力学和统计力学方法,计算Vapnik-Chervonenkis熵,该熵计算与损失类别兼容的不同二元分类的数量。作为概念的证明,我们专注于内核机器和最近物理学文献中介绍的两种简单的数据结构实现:具有规定的几何关系和球形流形(等效于边距分类)的三维单纯形。与严格的界限相反,熵与非结构化数据所发生的情况相反,其样本大小是非单调的。此外,数据结构引起了超出存储容量的转变,我们主张将其作为非单调性的代理,并最终提示低泛化误差。突触量在过渡期消失的识别可以量化复制理论内数据结构的影响,如我们无法进行组合学习的情况所示,适用于无法使用组合方法的情况。
更新日期:2020-09-14
中文翻译:
结构化数据的统计学习理论
统计物理学用于监督学习的传统方法通常假定数据的生成模型不切实际:通常,输入是独立的随机变量,与它们的标签无关。直到最近,统计物理学家才开始探索更复杂的数据形式,例如位于(可能是低维的)物体流形上的同样标记的点。在这里,我们提供了这个最近建立的研究领域与统计学习理论框架之间的桥梁,统计学习理论是专门用于机器学习推理的数学分支。总的动机是经典的严格结果不足以解释深度学习的显着概括特性。我们提出了一种将数据的物理模型集成到统计学习理论和地址中的方法,使用组合力学和统计力学方法,计算Vapnik-Chervonenkis熵,该熵计算与损失类别兼容的不同二元分类的数量。作为概念的证明,我们专注于内核机器和最近物理学文献中介绍的两种简单的数据结构实现:具有规定的几何关系和球形流形(等效于边距分类)的三维单纯形。与严格的界限相反,熵与非结构化数据所发生的情况相反,其样本大小是非单调的。此外,数据结构引起了超出存储容量的转变,我们主张将其作为非单调性的代理,并最终提示低泛化误差。突触量在过渡期消失的识别可以量化复制理论内数据结构的影响,如我们无法进行组合学习的情况所示,适用于无法使用组合方法的情况。
























 京公网安备 11010802027423号
京公网安备 11010802027423号