Cognition ( IF 4.011 ) Pub Date : 2020-08-21 , DOI: 10.1016/j.cognition.2020.104418 Aditya Upadhyayula 1 , Jonathan Flombaum 1
|
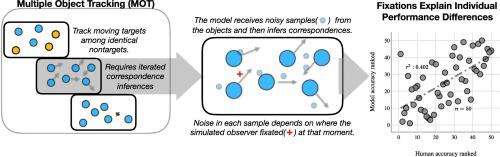
In many settings “keep your eye on the ball” is good advice. People fixate important objects to obtain high quality information. Perhaps equally often, however, we engage with multiple important, moving, and unpredictable objects. Where should we fixate in these situations, and where do we? Do we for example appropriately center fixations to manage spatial non-uniformity in our visual system? And do we fixate empty space strategically to gain as much information as possible about multiple objects of interest? We explored these issues in the context of Multiple Object Tracking (MOT), wherein observers track several moving objects (targets) within a larger set of moving objects (nontargets), all the objects physically indistinguishable from one another. Among the features that make MOT an interesting paradigm is that it cannot be accommodated by continuous gaze to one important object, because there are multiple such objects in a given trial. Instead, it demands sustained processing of inputs from an entire display and iterated inferences about target versus nontarget identities. MOT therefore demands a strategic interaction between eye movements and cognition: the observer should seek fixation locations that minimize the aggregate probability of confusing any target with any nontarget. Individuals who meet this fixation challenge should perform the task better than those who meet the challenge less effectively. Here we describe a probabilistic model that implements the basic computations needed to do MOT, estimating the positions of targets, predicting their future positions, and inferring correspondences between new inputs and represented targets. The quality of the input received by the model depends on its fixation location at a given moment. We simulated a group of fifty participants who all performed the same MOT trials, with the model adopting each observer's fixation locations in the respective simulations. The model reliably predicted individual participant tracking performances and their relative rankings within the cohort. The results suggest that an individual's relative capability in this cognitively demanding task is in part determined by his/her utilization of eye fixations to control the quality and relevance of incoming visual input.
中文翻译:
采用人为注视的模型解释了多对象跟踪中的个体差异。
在许多情况下,“保持警惕”是一个很好的建议。人们固定重要物体以获得高质量的信息。但是,也许同样经常地,我们与多个重要的,移动的且不可预测的对象进行接触。在这种情况下,我们应该将注意力集中在哪里?例如,我们是否适当地对中注视,以管理视觉系统中的空间不均匀性?我们是否从战略上固定了空白空间以获取有关多个感兴趣物体的尽可能多的信息?我们在多对象跟踪(MOT)的背景下探讨了这些问题,其中观察者跟踪了一组较大的移动对象(非目标)中的几个移动对象(目标),所有对象在物理上都无法区分。使MOT成为一种有趣的范例的特征之一是,连续注视一个重要的对象不能适应它,因为在给定的试验中有多个这样的对象。取而代之的是,它要求对整个显示器的输入进行持续处理,并反复推断目标和非目标身份。因此,MOT需要在眼球运动和认知之间进行战略性互动:观察者应寻找固定位置,以最大程度地减少将任何目标与任何非目标混淆的总概率。遇到固定挑战的人应比那些挑战效率较低的人更好地完成任务。在这里,我们描述了一个概率模型,该模型实现了进行MOT所需的基本计算,估算目标的位置,预测目标的未来位置,并推断新输入和代表目标之间的对应关系。模型接收的输入质量取决于给定时刻的固定位置。我们模拟了一组五十人,他们都进行了相同的MOT试验,并且模型在各自的模拟中采用了每个观察者的注视位置。该模型可靠地预测了队列中各个参与者的跟踪表现及其相对排名。结果表明,个人在此认知要求较高的任务中的相对能力部分取决于他/她对眼动装置的利用,以控制传入视觉输入的质量和相关性。我们模拟了一组五十人,他们都进行了相同的MOT试验,并且模型在各自的模拟中采用了每个观察者的注视位置。该模型可靠地预测了队列中各个参与者的跟踪表现及其相对排名。结果表明,个人在此认知要求较高的任务中的相对能力部分取决于他/她对眼动装置的利用,以控制传入视觉输入的质量和相关性。我们模拟了一组五十人,他们都进行了相同的MOT试验,并且模型在各自的模拟中采用了每个观察者的注视位置。该模型可靠地预测了队列中各个参与者的跟踪表现及其相对排名。结果表明,个人在此认知要求较高的任务中的相对能力部分取决于他/她对眼动装置的利用,以控制传入视觉输入的质量和相关性。

























 京公网安备 11010802027423号
京公网安备 11010802027423号