当前位置:
X-MOL 学术
›
Anal. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Symbolic Aggregate Approximation Improves Gap Filling in High-Resolution Mass Spectrometry Data Processing.
Analytical Chemistry ( IF 7.4 ) Pub Date : 2020-07-27 , DOI: 10.1021/acs.analchem.0c00899 Erik Müller 1, 2 , Carolin Elisabeth Huber 1, 2 , Werner Brack 1, 2 , Martin Krauss 1 , Tobias Schulze 1
Analytical Chemistry ( IF 7.4 ) Pub Date : 2020-07-27 , DOI: 10.1021/acs.analchem.0c00899 Erik Müller 1, 2 , Carolin Elisabeth Huber 1, 2 , Werner Brack 1, 2 , Martin Krauss 1 , Tobias Schulze 1
Affiliation
|
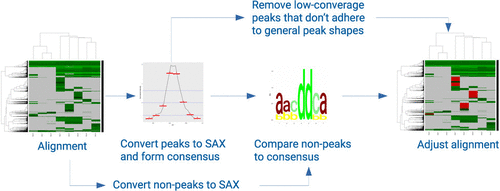
Nontargeted mass spectrometry (MS) is widely used in life sciences and environmental chemistry to investigate large sets of samples. A major problem for larger-scale MS studies is data gaps or missing values in aligned data sets. The main causes for these data gaps are the absence of the compound from the sample, issues related to chromatography or mass spectrometry (for example, broad peaks, early eluting peaks, ion suppression, low ionization efficiency), and issues related to software (mainly limitations of peak detection algorithms). While those algorithms are heuristic by necessity and should be used with strict settings to minimize the number of false positive and negative peaks in a data set, gap filling may be used to reduce missing data in single samples remaining after peak detection. In this study, we present a new gap filling algorithm. The method is based on the symbolic aggregation approximation (SAX) algorithm that was developed for the evaluation and classification of time series in data mining studies. We adopted SAX for liquid chromatography high-resolution MS nontarget screening to support the detection of missing peaks in aligned mass spectral data sets. The SAX-based algorithm improves the detection efficiency considerably compared to existing gap filling methods including the Peak Finder algorithm provided in MZmine.
中文翻译:

符号集合近似可改善高分辨率质谱数据处理中的间隙填充。
非目标质谱(MS)在生命科学和环境化学中广泛用于研究大量样品。大规模质谱研究的主要问题是对齐的数据集中的数据缺口或缺失值。这些数据缺口的主要原因是样品中不存在化合物,与色谱法或质谱法有关的问题(例如,宽峰,早期洗脱峰,离子抑制,电离效率低)以及与软件有关的问题(主要是峰值检测算法的局限性)。尽管这些算法是必要的启发式算法,应在严格的设置下使用,以最大程度地减少数据集中虚假正负峰的数量,但可以使用空位填充来减少峰值检测后剩余的单个样本中的丢失数据。在这项研究中,我们提出了一种新的缺口填充算法。该方法基于为数据挖掘研究中的时间序列评估和分类而开发的符号聚合近似(SAX)算法。我们采用SAX进行液相色谱高分辨率MS非目标筛查,以支持检测对齐的质谱数据集中缺少的峰。与现有的间隙填充方法(包括MZmine中提供的Peak Finder算法)相比,基于SAX的算法大大提高了检测效率。
更新日期:2020-08-04
中文翻译:
符号集合近似可改善高分辨率质谱数据处理中的间隙填充。
非目标质谱(MS)在生命科学和环境化学中广泛用于研究大量样品。大规模质谱研究的主要问题是对齐的数据集中的数据缺口或缺失值。这些数据缺口的主要原因是样品中不存在化合物,与色谱法或质谱法有关的问题(例如,宽峰,早期洗脱峰,离子抑制,电离效率低)以及与软件有关的问题(主要是峰值检测算法的局限性)。尽管这些算法是必要的启发式算法,应在严格的设置下使用,以最大程度地减少数据集中虚假正负峰的数量,但可以使用空位填充来减少峰值检测后剩余的单个样本中的丢失数据。在这项研究中,我们提出了一种新的缺口填充算法。该方法基于为数据挖掘研究中的时间序列评估和分类而开发的符号聚合近似(SAX)算法。我们采用SAX进行液相色谱高分辨率MS非目标筛查,以支持检测对齐的质谱数据集中缺少的峰。与现有的间隙填充方法(包括MZmine中提供的Peak Finder算法)相比,基于SAX的算法大大提高了检测效率。


























 京公网安备 11010802027423号
京公网安备 11010802027423号