当前位置:
X-MOL 学术
›
React. Chem. Eng.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Data fusion by joint non-negative matrix factorization for hypothesizing pseudo-chemistry using Bayesian networks
Reaction Chemistry & Engineering ( IF 3.9 ) Pub Date : 2020-07-07 , DOI: 10.1039/d0re00147c Anjana Puliyanda 1, 2, 3 , Kaushik Sivaramakrishnan 1, 2, 3 , Zukui Li 1, 2, 3 , Arno de Klerk 1, 2, 3 , Vinay Prasad 1, 2, 3
Reaction Chemistry & Engineering ( IF 3.9 ) Pub Date : 2020-07-07 , DOI: 10.1039/d0re00147c Anjana Puliyanda 1, 2, 3 , Kaushik Sivaramakrishnan 1, 2, 3 , Zukui Li 1, 2, 3 , Arno de Klerk 1, 2, 3 , Vinay Prasad 1, 2, 3
Affiliation
|
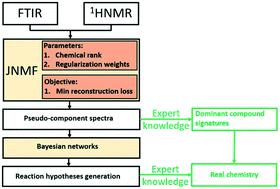
Inferring the reaction pathways underlying the processing of complex feeds, using noisy data from spectral sensors that may contain information regarding molecular mechanisms, is challenging. This is tackled by a two-step approach for the partial upgrading of Cold Lake bitumen: first, joint non-negative matrix factorization (JNMF) is used as a data fusion algorithm to extract pseudocomponent spectra by combining complementary information about the reacting environment from Fourier transform infrared (FTIR) and proton nuclear magnetic resonance (1H-NMR) spectroscopic sensors. Second, a probabilistic inferential model that hypothesizes reaction mechanisms among the identified pseudocomponent spectra is constructed using Bayesian networks that encode directed acyclic causal pathways among the nodes of the random variables (pseudocomponent spectra). The JNMF algorithm has been developed to handle process data artefacts by imputing missing data, using a rotationally invariant norm for robustness to outliers and noise, and enforcing the non-negativity constraint to ensure physical interpretability in compliance with Beer's law for spectral data. The projected optimal gradient approach developed to solve the JNMF objective converges within fewer iterations at the specified tolerance as compared to the multiplicative update rules (MUR). Solution ambiguity in JNMF is limited by incorporating graph regularization terms: (a) inter-sensor co-regularization that penalizes redundancy in the pseudocomponent spectra across spectral sensors, and (b) intra-spectral manifold regularization that penalizes overfitting of the pseudocomponent spectra from each sensor by penalizing redundant peaks within a spectrum. Weighting the intra-spectral regularization term that minimizes similarly correlated peaks across spectral channels of a sensor to zero is seen to result in chemically meaningful pseudocomponent spectra, given that different organic compounds share similar properties with respect to their hydrocarbon structure. Hence, the preferential weighting of regularizers is shown to act as a chemical information sieve by controlling the peaks that appear in the pseudocomponent spectra, thereby enabling the proposal of different reaction mechanisms, based on the similarity metric used to model the graph structure.
中文翻译:

通过联合非负矩阵分解进行数据融合以使用贝叶斯网络假设假化学
利用光谱传感器中可能包含有关分子机制信息的嘈杂数据来推断复杂进料加工背后的反应途径具有挑战性。这是通过两步方法对冷湖沥青进行部分升级来解决的:首先,联合非负矩阵因式分解(JNMF)作为数据融合算法,通过结合有关傅里叶反应环境的补充信息来提取伪组分光谱变换红外(FTIR)和质子核磁共振(1H-NMR)光谱传感器。其次,使用贝叶斯网络构建一个假设推断模型,该模型在识别出的伪组分谱之间的反应机理进行假设,该网络对随机变量的节点(伪组分谱)之间的有向无环因果路径进行编码。JNMF算法已被开发来处理过程数据伪像,方法是通过插补缺失数据,使用旋转不变范数来增强对异常值和噪声的鲁棒性,并强制采用非负性约束条件,以确保符合光谱数据的比尔定律的物理可解释性。与乘法更新规则(MUR)相比,为解决JNMF目标而开发的预计最佳梯度方法以指定的公差在较少的迭代中收敛。JNMF中的解决方案歧义性受以下因素的限制:合并图正则化项:(a)传感器间共正则化,惩罚了跨光谱传感器的伪分量谱中的冗余,以及(b)光谱内歧管正则化,惩罚了每个伪谱的过度拟合通过惩罚频谱内的冗余峰值来补偿传感器。假设将不同有机化合物在其碳氢化合物结构方面具有相似的特性,那么将光谱内的正则化项权重最小化,可以使传感器的光谱通道上的相似相关峰最小化为零,这会产生化学上有意义的伪组分光谱。因此,通过控制伪组分光谱中出现的峰,正则化剂的优先权重显示为化学信息筛,
更新日期:2020-08-25
中文翻译:
通过联合非负矩阵分解进行数据融合以使用贝叶斯网络假设假化学
利用光谱传感器中可能包含有关分子机制信息的嘈杂数据来推断复杂进料加工背后的反应途径具有挑战性。这是通过两步方法对冷湖沥青进行部分升级来解决的:首先,联合非负矩阵因式分解(JNMF)作为数据融合算法,通过结合有关傅里叶反应环境的补充信息来提取伪组分光谱变换红外(FTIR)和质子核磁共振(1H-NMR)光谱传感器。其次,使用贝叶斯网络构建一个假设推断模型,该模型在识别出的伪组分谱之间的反应机理进行假设,该网络对随机变量的节点(伪组分谱)之间的有向无环因果路径进行编码。JNMF算法已被开发来处理过程数据伪像,方法是通过插补缺失数据,使用旋转不变范数来增强对异常值和噪声的鲁棒性,并强制采用非负性约束条件,以确保符合光谱数据的比尔定律的物理可解释性。与乘法更新规则(MUR)相比,为解决JNMF目标而开发的预计最佳梯度方法以指定的公差在较少的迭代中收敛。JNMF中的解决方案歧义性受以下因素的限制:合并图正则化项:(a)传感器间共正则化,惩罚了跨光谱传感器的伪分量谱中的冗余,以及(b)光谱内歧管正则化,惩罚了每个伪谱的过度拟合通过惩罚频谱内的冗余峰值来补偿传感器。假设将不同有机化合物在其碳氢化合物结构方面具有相似的特性,那么将光谱内的正则化项权重最小化,可以使传感器的光谱通道上的相似相关峰最小化为零,这会产生化学上有意义的伪组分光谱。因此,通过控制伪组分光谱中出现的峰,正则化剂的优先权重显示为化学信息筛,


























 京公网安备 11010802027423号
京公网安备 11010802027423号