当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Data Augmentation and Pretraining for Template-Based Retrosynthetic Prediction in Computer-Aided Synthesis Planning.
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2020-06-22 , DOI: 10.1021/acs.jcim.0c00403 Michael E Fortunato 1 , Connor W Coley 1 , Brian C Barnes 2 , Klavs F Jensen 1
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2020-06-22 , DOI: 10.1021/acs.jcim.0c00403 Michael E Fortunato 1 , Connor W Coley 1 , Brian C Barnes 2 , Klavs F Jensen 1
Affiliation
|
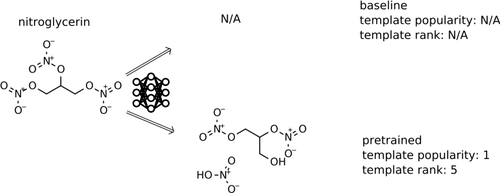
This work presents efforts to augment the performance of data-driven machine learning algorithms for reaction template recommendation used in computer-aided synthesis planning software. Often, machine learning models designed to perform the task of prioritizing reaction templates or molecular transformations are focused on reporting high-accuracy metrics for the one-to-one mapping of product molecules in reaction databases to the template extracted from the recorded reaction. The available templates that get selected for inclusion in these machine learning models have been previously limited to those that appear frequently in the reaction databases and exclude potentially useful transformations. By augmenting open-access data sets of organic reactions with explicitly calculated template applicability and pretraining a template-relevance neural network on this augmented applicability data set, we report an increase in the template applicability recall and an increase in the diversity of predicted precursors. The augmentation and pretraining effectively teaches the neural network an increased set of templates that could theoretically lead to successful reactions for a given target. Even on a small data set of well-curated reactions, the data augmentation and pretraining methods resulted in an increase in top-1 accuracy, especially for rare templates, indicating that these strategies can be very useful for small data sets.
中文翻译:

计算机辅助综合计划中基于模板的逆向合成预测的数据增强和预训练。
这项工作提出了努力,以增强数据驱动的机器学习算法的性能,以用于计算机辅助综合计划软件中使用的反应模板推荐。通常,旨在执行对反应模板或分子转化进行优先排序的任务的机器学习模型专注于报告高精度指标,以将反应数据库中的产物分子与从记录的反应中提取的模板进行一对一映射。以前选择要包含在这些机器学习模型中的可用模板,以前仅限于在反应数据库中频繁出现的模板,并排除了可能有用的转换。通过使用显式计算的模板适用性来扩展有机反应的开放获取数据集,并在此扩展的适用性数据集上对模板相关的神经网络进行预训练,我们报告了模板适用性的提高和预计前体多样性的增加。增强和预训练有效地向神经网络教授了一组增加的模板,这些模板在理论上可以导致针对给定目标的成功反应。即使是在精心策划的反应的小型数据集上,数据扩充和预训练方法也会提高top-1准确性,尤其是对于稀有模板,这表明这些策略对于小型数据集可能非常有用。我们报告了模板适用性召回的增加以及预测前体的多样性的增加。增强和预训练有效地向神经网络教授了一组增加的模板,这些模板在理论上可以导致针对给定目标的成功反应。即使是在精心策划的反应的小型数据集上,数据扩充和预训练方法也会提高top-1准确性,尤其是对于稀有模板,这表明这些策略对于小型数据集可能非常有用。我们报告了模板适用性召回的增加以及预测前体的多样性的增加。增强和预训练有效地向神经网络教授了一组增加的模板,这些模板在理论上可以导致针对给定目标的成功反应。即使是在精心策划的反应的小型数据集上,数据扩充和预训练方法也会提高top-1准确性,尤其是对于稀有模板,这表明这些策略对于小型数据集可能非常有用。
更新日期:2020-07-27
中文翻译:
计算机辅助综合计划中基于模板的逆向合成预测的数据增强和预训练。
这项工作提出了努力,以增强数据驱动的机器学习算法的性能,以用于计算机辅助综合计划软件中使用的反应模板推荐。通常,旨在执行对反应模板或分子转化进行优先排序的任务的机器学习模型专注于报告高精度指标,以将反应数据库中的产物分子与从记录的反应中提取的模板进行一对一映射。以前选择要包含在这些机器学习模型中的可用模板,以前仅限于在反应数据库中频繁出现的模板,并排除了可能有用的转换。通过使用显式计算的模板适用性来扩展有机反应的开放获取数据集,并在此扩展的适用性数据集上对模板相关的神经网络进行预训练,我们报告了模板适用性的提高和预计前体多样性的增加。增强和预训练有效地向神经网络教授了一组增加的模板,这些模板在理论上可以导致针对给定目标的成功反应。即使是在精心策划的反应的小型数据集上,数据扩充和预训练方法也会提高top-1准确性,尤其是对于稀有模板,这表明这些策略对于小型数据集可能非常有用。我们报告了模板适用性召回的增加以及预测前体的多样性的增加。增强和预训练有效地向神经网络教授了一组增加的模板,这些模板在理论上可以导致针对给定目标的成功反应。即使是在精心策划的反应的小型数据集上,数据扩充和预训练方法也会提高top-1准确性,尤其是对于稀有模板,这表明这些策略对于小型数据集可能非常有用。我们报告了模板适用性召回的增加以及预测前体的多样性的增加。增强和预训练有效地向神经网络教授了一组增加的模板,这些模板在理论上可以导致针对给定目标的成功反应。即使是在精心策划的反应的小型数据集上,数据扩充和预训练方法也会提高top-1准确性,尤其是对于稀有模板,这表明这些策略对于小型数据集可能非常有用。

























 京公网安备 11010802027423号
京公网安备 11010802027423号