当前位置:
X-MOL 学术
›
Anal. Methods
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
An approach for feature selection with data modelling in LC-MS metabolomics.
Analytical Methods ( IF 3.1 ) Pub Date : 2020-06-15 , DOI: 10.1039/d0ay00204f Ivan Plyushchenko 1 , Dmitry Shakhmatov , Timofey Bolotnik , Timur Baygildiev , Pavel N Nesterenko , Igor Rodin
Analytical Methods ( IF 3.1 ) Pub Date : 2020-06-15 , DOI: 10.1039/d0ay00204f Ivan Plyushchenko 1 , Dmitry Shakhmatov , Timofey Bolotnik , Timur Baygildiev , Pavel N Nesterenko , Igor Rodin
Affiliation
|
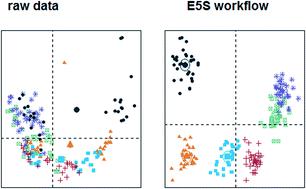
The data processing workflow for LC-MS based metabolomics study is suggested with signal drift correction, univariate analysis, supervised learning, feature selection and unsupervised modelling. The proposed approach requires only an annotation-free peak table and produces an extremely reduced set of the most relevant features together with validation via Receiver Operating Characteristic analysis for selected predictors, cross-validation and unsupervised projection. The presented study was initially optimised by its own experimental set and then was successfully tested by using 36 datasets from 21 publicly available metabolomics projects. The suggested workflow can be used for classification purposes in high dimensional metabolomics studies and as a first step in exploratory analysis, data projection, biomarker selection, data integration and fusion.
中文翻译:

LC-MS代谢组学中数据建模的特征选择方法。
建议基于LC-MS的代谢组学研究的数据处理工作流程,包括信号漂移校正,单变量分析,监督学习,特征选择和无监督建模。所提出的方法仅需要一个无注释的峰表,并通过极为有效的验证减少了一组最相关的功能。针对选定预测变量,交叉验证和无监督预测的接收器运行特征分析。提出的研究最初通过其自己的实验集进行了优化,然后使用来自21个可公开获得的代谢组学项目的36个数据集进行了成功测试。建议的工作流程可用于高维代谢组学研究中的分类目的,以及作为探索性分析,数据投影,生物标志物选择,数据集成和融合的第一步。
更新日期:2020-07-23
中文翻译:
LC-MS代谢组学中数据建模的特征选择方法。
建议基于LC-MS的代谢组学研究的数据处理工作流程,包括信号漂移校正,单变量分析,监督学习,特征选择和无监督建模。所提出的方法仅需要一个无注释的峰表,并通过极为有效的验证减少了一组最相关的功能。针对选定预测变量,交叉验证和无监督预测的接收器运行特征分析。提出的研究最初通过其自己的实验集进行了优化,然后使用来自21个可公开获得的代谢组学项目的36个数据集进行了成功测试。建议的工作流程可用于高维代谢组学研究中的分类目的,以及作为探索性分析,数据投影,生物标志物选择,数据集成和融合的第一步。

























 京公网安备 11010802027423号
京公网安备 11010802027423号