IRBM ( IF 4.8 ) Pub Date : 2020-05-22 , DOI: 10.1016/j.irbm.2020.05.005 M.M. Rahman , Y. Ghasemi , E. Suley , Y. Zhou , S. Wang , J. Rogers
|
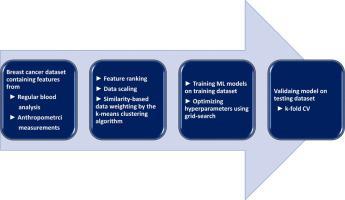
Breast cancer is one of the most prevalent types of cancers in females, which has become rampant all over the world in recent years. The survival rate of breast cancer patients degrades considerably for patients diagnosed at an advanced stage compared to those diagnosed at an early stage. The objective of this study is two folds. The first one is to find the most relevant biomarkers of breast cancer, which can be attained from regular blood analysis and anthropometric measurements. The other one is to improve the performance of current computer-aided diagnosis (CAD) system of early breast cancer detection. This study utilized a recent data set containing nine anthropometric and clinical attributes. In our methodology, first, we performed multicollinearity analysis and ranked the features based on the weighted average score obtained from four filter-based feature evaluation methods such as F-score, information gain, chi-square statistic, and Minimum Redundancy Maximum Relevance. Next, to improve the separability of the target classes, we scaled and weighted the dataset using min-max normalization and similarity-based attribute weighting by the k-means clustering algorithm, respectively. Finally, we trained standard machine learning (ML) models and evaluated the performance metrics by 10-fold cross-validation method. Our support vector machine (SVM) model with radial basis function (RBF) kernel appeared to be the most successful classifier by utilizing six features, namely, Body Mass Index (BMI), Age, Glucose, MCP-1, Resistin, and Insulin. The obtained classification accuracy, sensitivity, and specificity are 93.9% (95% CI: 93.2–94.6%), 95.1% (95% CI: 94.4–95.8%), and 94.0% (95% CI: 93.3–94.7%), respectively; these performance metrics outperformed state-of-the-art methods reported in the literature. The developed model could potentially assist the medical experts for the early diagnosis of breast cancer by employing a set of attributes that can be easily obtained from regular blood analysis and anthropometric measurements.
中文翻译:
利用人体测量学和临床特征进行基于机器学习的乳腺癌计算机辅助诊断
乳腺癌是女性最常见的癌症类型之一,近年来在世界范围内变得猖獗。与早期诊断的乳腺癌患者相比,晚期诊断的乳腺癌患者的生存率显着降低。本研究的目的有两个。第一个是找到与乳腺癌最相关的生物标志物,这可以通过常规血液分析和人体测量获得。另一个是提高当前早期乳腺癌检测的计算机辅助诊断(CAD)系统的性能。本研究利用了包含九个人体测量学和临床属性的最新数据集。在我们的方法中,首先,我们进行了多重共线性分析,并根据从四种基于滤波器的特征评估方法(例如 F 分数、信息增益、卡方统计量和最小冗余最大相关性)获得的加权平均分数对特征进行排序。接下来,为了提高目标类的可分离性,我们分别使用 min-max 归一化和 k-means 聚类算法基于相似性的属性加权对数据集进行缩放和加权。最后,我们训练标准机器学习 (ML) 模型并通过 10 倍交叉验证方法评估性能指标。我们的具有径向基函数 (RBF) 核的支持向量机 (SVM) 模型似乎是最成功的分类器,它利用了六个特征,即体重指数 (BMI)、年龄、葡萄糖、MCP-1、抵抗素和胰岛素。获得的分类准确率、敏感性和特异性分别为 93.9% (95% CI: 93.2–94.6%)、95.1% (95% CI: 94.4–95.8%) 和 94.0% (95% CI: 93.3–94.7%),分别; 这些性能指标优于文献中报道的最先进的方法。开发的模型可以通过使用一组可以从常规血液分析和人体测量中轻松获得的属性来帮助医学专家对乳腺癌进行早期诊断。
























 京公网安备 11010802027423号
京公网安备 11010802027423号