Image and Vision Computing ( IF 4.7 ) Pub Date : 2020-05-18 , DOI: 10.1016/j.imavis.2020.103932 Bharti Munjal , Abdul Rafey Aftab , Sikandar Amin , Meltem D. Brandlmaier , Federico Tombari , Fabio Galasso
|
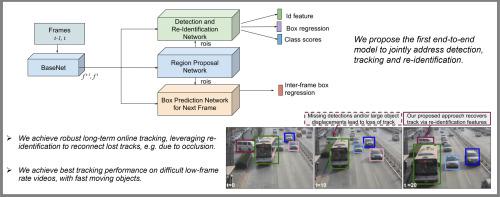
Recent works have shown that combining object detection and tracking tasks, in the case of video data, results in higher performance for both tasks, but they require a high frame-rate as a strict requirement for performance. This assumption is often violated in real-world applications, when models run on embedded devices, often at only a few frames per second.
Videos at low frame-rate suffer from large object displacements. Here re-identification features may support to match large-displaced object detections, but current joint detection and re-identification formulations degrade the detector performance, as these two are contrasting tasks. In the real-world application having separate detector and re-id models is often not feasible, as both the memory and runtime effectively double.
Towards robust long-term tracking applicable to reduced-computational-power devices, we propose the first joint optimization of detection, tracking and re-identification features for videos. Notably, our joint optimization maintains the detector performance, a typical multi-task challenge. At inference time, we leverage detections for tracking (tracking-by-detection) when the objects are visible, detectable and slowly moving in the image. We leverage instead re-identification features to match objects which disappeared (e.g. due to occlusion) for several frames or were not tracked due to fast motion (or low-frame-rate videos). Our proposed method reaches the state-of-the-art on MOT, it ranks 1st in the UA-DETRAC’18 tracking challenge among online trackers, and 3rd overall.
中文翻译:
具有识别功能的视频联合检测和跟踪
最近的工作表明,在视频数据的情况下,将对象检测和跟踪任务组合在一起可以提高两个任务的性能,但是作为对性能的严格要求,它们需要很高的帧速率。当模型在嵌入式设备上运行时,通常仅以每秒几帧的速度运行,在现实世界的应用程序中经常会违反此假设。
低帧频的视频会产生较大的对象位移。此处的重新识别功能可能支持匹配大位移的对象检测,但是当前的联合检测和重新识别公式会降低检测器性能,因为这是两个对比任务。在实际应用中,具有单独的检测器模型和re-id模型通常是不可行的,因为内存和运行时间实际上都加倍了。
为了实现适用于降低计算功率设备的鲁棒的长期跟踪,我们建议对视频的检测,跟踪和重新识别功能进行首次联合优化。值得注意的是,我们的联合优化可保持检测器性能,这是典型的多任务挑战。在推断时,当物体在图像中可见,可检测并缓慢移动时,我们利用检测进行跟踪(逐条跟踪)。相反,我们利用重新识别功能来匹配已消失(例如由于遮挡)几帧或由于快速运动(或低帧速视频)而无法跟踪的对象。我们提出的方法已达到MOT的最新水平,在UA-DETRAC'18追踪挑战中在线追踪器中排名第一,整体排名第三。

























 京公网安备 11010802027423号
京公网安备 11010802027423号