当前位置:
X-MOL 学术
›
J. Biomed. Inform.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Active deep learning to detect demographic traits in free-form clinical notes.
Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-05-16 , DOI: 10.1016/j.jbi.2020.103436 Amir Feder 1 , Danny Vainstein 2 , Roni Rosenfeld 3 , Tzvika Hartman 4 , Avinatan Hassidim 4 , Yossi Matias 4
Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-05-16 , DOI: 10.1016/j.jbi.2020.103436 Amir Feder 1 , Danny Vainstein 2 , Roni Rosenfeld 3 , Tzvika Hartman 4 , Avinatan Hassidim 4 , Yossi Matias 4
Affiliation
|
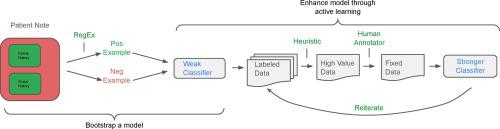
The free-form portions of clinical notes are a significant source of information for research, but before they can be used, they must be de-identified to protect patients' privacy. De-identification efforts have focused on known identifier types (names, ages, dates, addresses, ID's, etc.). However, a note can contain residual "Demographic Traits" (DTs), unique enough to re-identify the patient when combined with other such facts. Here we examine whether any residual risks remain after removing these identifiers. After manually annotating over 140,000 words worth of medical notes, we found no remaining directly identifying information, and a low prevalence of demographic traits, such as marital status or housing type. We developed an annotation guide to the discovered Demographic Traits (DTs) and used it to label MIMIC-III and i2b2-2006 clinical notes as test sets. We then designed a "bootstrapped" active learning iterative process for identifying DTs: we tentatively labeled as positive all sentences in the DT-rich note sections, used these to train a binary classifier, manually corrected acute errors, and retrained the classifier. This train-and-correct process may be iterated. Our active learning process significantly improved the classifier's accuracy. Moreover, our BERT-based model outperformed non-neural models when trained on both tentatively labeled data and manually relabeled examples. To facilitate future research and benchmarking, we also produced and made publicly available our human annotated DT-tagged datasets. We conclude that directly identifying information is virtually non-existent in the multiple medical note types we investigated. Demographic traits are present in medical notes, but can be detected with high accuracy using a cost-effective human-in-the-loop active learning process, and redacted if desired.2.
中文翻译:

主动深度学习以检测自由形式的临床笔记中的人口统计学特征。
临床笔记的自由形式部分是重要的研究信息来源,但是在使用它们之前,必须先对它们进行标识,以保护患者的隐私。取消标识的工作集中在已知的标识符类型(名称,年龄,日期,地址,ID等)上。但是,笔记可能包含残留的“人口统计特征”(DT),当与其他此类事实相结合时,其独特性足以重新识别患者。在这里,我们检查了删除这些标识符后是否还有任何剩余风险。在手动注释了超过14万个单词的医疗记录后,我们发现没有剩余的直接识别信息,而且人口统计特征(例如婚姻状况或住房类型)的患病率较低。我们针对发现的人口统计学特征(DT)开发了注释指南,并使用该指南将MIMIC-III和i2b2-2006临床笔记标记为测试集。然后,我们设计了一种用于识别DT的“自举式”主动学习迭代过程:我们将DT丰富的音符部分中的所有句子都暂时标记为肯定,使用它们来训练二进制分类器,手动纠正的严重错误并重新训练分类器。此训练和纠正过程可能会重复进行。我们积极的学习过程大大提高了分类器的准确性。此外,在临时标记的数据和手动重新标记的示例上进行训练时,基于BERT的模型优于非神经模型。为了促进将来的研究和基准测试,我们还制作并公开了带有人工注释的DT标签的数据集。我们得出的结论是,在我们调查的多种医学笔记类型中,几乎没有直接识别信息的信息。人口统计特征存在于医学笔记中,但可以使用具有成本效益的人在环主动学习过程进行高精度检测,并根据需要进行编辑。2。
更新日期:2020-05-16
中文翻译:
主动深度学习以检测自由形式的临床笔记中的人口统计学特征。
临床笔记的自由形式部分是重要的研究信息来源,但是在使用它们之前,必须先对它们进行标识,以保护患者的隐私。取消标识的工作集中在已知的标识符类型(名称,年龄,日期,地址,ID等)上。但是,笔记可能包含残留的“人口统计特征”(DT),当与其他此类事实相结合时,其独特性足以重新识别患者。在这里,我们检查了删除这些标识符后是否还有任何剩余风险。在手动注释了超过14万个单词的医疗记录后,我们发现没有剩余的直接识别信息,而且人口统计特征(例如婚姻状况或住房类型)的患病率较低。我们针对发现的人口统计学特征(DT)开发了注释指南,并使用该指南将MIMIC-III和i2b2-2006临床笔记标记为测试集。然后,我们设计了一种用于识别DT的“自举式”主动学习迭代过程:我们将DT丰富的音符部分中的所有句子都暂时标记为肯定,使用它们来训练二进制分类器,手动纠正的严重错误并重新训练分类器。此训练和纠正过程可能会重复进行。我们积极的学习过程大大提高了分类器的准确性。此外,在临时标记的数据和手动重新标记的示例上进行训练时,基于BERT的模型优于非神经模型。为了促进将来的研究和基准测试,我们还制作并公开了带有人工注释的DT标签的数据集。我们得出的结论是,在我们调查的多种医学笔记类型中,几乎没有直接识别信息的信息。人口统计特征存在于医学笔记中,但可以使用具有成本效益的人在环主动学习过程进行高精度检测,并根据需要进行编辑。2。
























 京公网安备 11010802027423号
京公网安备 11010802027423号