当前位置:
X-MOL 学术
›
Chem. Bio. Drug Des.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Common cancer biomarkers of breast and ovarian types identified through artificial intelligence.
Chemical Biology & Drug Design ( IF 3 ) Pub Date : 2020-05-15 , DOI: 10.1111/cbdd.13672 Shrikant Pawar 1 , Tuck Onn Liew 2 , Aditya Stanam 3 , Chandrajit Lahiri 2
Chemical Biology & Drug Design ( IF 3 ) Pub Date : 2020-05-15 , DOI: 10.1111/cbdd.13672 Shrikant Pawar 1 , Tuck Onn Liew 2 , Aditya Stanam 3 , Chandrajit Lahiri 2
Affiliation
|
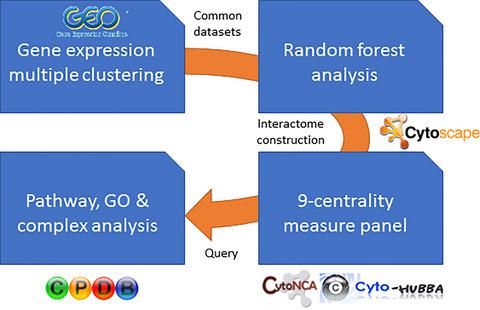
Biomarkers can offer great promise for improving prevention and treatment of complex diseases such as cancer, cardiovascular diseases, and diabetes. These can be used as either diagnostic or predictive or as prognostic biomarkers. The revolution brought about in biological big data analytics by artificial intelligence (AI) has the potential to identify a broader range of genetic differences and support the generation of more robust biomarkers in medicine. AI is invigorating biomarker research on various fronts, right from the cataloguing of key mutations driving the complex diseases like cancer to the elucidation of molecular networks underlying diseases. In this study, we have explored the potential of AI through machine learning approaches to propose that these methods can act as recommendation systems to sort and prioritize important genes and finally predict the presence of specific biomarkers. Essentially, we have utilized microarray datasets from open‐source databases, like GEO, for breast, lung, colon, and ovarian cancer. In this context, different clustering analyses like hierarchical and k‐means along with random forest algorithm have been utilized to classify important genes from a pool of several thousand genes. To this end, network centrality and pathway analysis have been implemented to identify the most potential target as CREB1.
中文翻译:

通过人工智能识别出的乳腺癌和卵巢癌的常见生物标志物。
生物标志物可以为改善预防和治疗癌症,心血管疾病和糖尿病等复杂疾病提供巨大希望。这些可以用作诊断性或预测性或预后性生物标志物。人工智能(AI)在生物大数据分析中带来的革命有潜力识别更广泛的遗传差异,并支持在医学中生成更强大的生物标记。从驱动癌症等复杂疾病的关键突变的分类到阐明疾病基础的分子网络等各个方面,人工智能都在推动生物标记研究的各个方面。在这个研究中,我们已经通过机器学习方法探索了AI的潜力,提出这些方法可以作为推荐系统来对重要基因进行排序和优先排序,并最终预测特定生物标记的存在。从本质上讲,我们利用了来自开源数据库(如GEO)的微阵列数据集来治疗乳腺癌,肺癌,结肠癌和卵巢癌。在这种情况下,已经采用了不同的聚类分析,例如分层和k-均值以及随机森林算法,来对数千个基因库中的重要基因进行分类。为此,已经实施了网络中心性和路径分析,以将最可能的目标确定为CREB1。和卵巢癌。在这种情况下,已经采用了不同的聚类分析,例如分层和k-均值以及随机森林算法,来对数千个基因库中的重要基因进行分类。为此,已经实施了网络中心性和路径分析,以将最可能的目标确定为CREB1。和卵巢癌。在这种情况下,已经采用了不同的聚类分析,例如分层和k-均值以及随机森林算法,来对数千个基因库中的重要基因进行分类。为此,已经实施了网络中心性和路径分析,以将最可能的目标确定为CREB1。
更新日期:2020-05-15
中文翻译:
通过人工智能识别出的乳腺癌和卵巢癌的常见生物标志物。
生物标志物可以为改善预防和治疗癌症,心血管疾病和糖尿病等复杂疾病提供巨大希望。这些可以用作诊断性或预测性或预后性生物标志物。人工智能(AI)在生物大数据分析中带来的革命有潜力识别更广泛的遗传差异,并支持在医学中生成更强大的生物标记。从驱动癌症等复杂疾病的关键突变的分类到阐明疾病基础的分子网络等各个方面,人工智能都在推动生物标记研究的各个方面。在这个研究中,我们已经通过机器学习方法探索了AI的潜力,提出这些方法可以作为推荐系统来对重要基因进行排序和优先排序,并最终预测特定生物标记的存在。从本质上讲,我们利用了来自开源数据库(如GEO)的微阵列数据集来治疗乳腺癌,肺癌,结肠癌和卵巢癌。在这种情况下,已经采用了不同的聚类分析,例如分层和k-均值以及随机森林算法,来对数千个基因库中的重要基因进行分类。为此,已经实施了网络中心性和路径分析,以将最可能的目标确定为CREB1。和卵巢癌。在这种情况下,已经采用了不同的聚类分析,例如分层和k-均值以及随机森林算法,来对数千个基因库中的重要基因进行分类。为此,已经实施了网络中心性和路径分析,以将最可能的目标确定为CREB1。和卵巢癌。在这种情况下,已经采用了不同的聚类分析,例如分层和k-均值以及随机森林算法,来对数千个基因库中的重要基因进行分类。为此,已经实施了网络中心性和路径分析,以将最可能的目标确定为CREB1。


























 京公网安备 11010802027423号
京公网安备 11010802027423号