Applied Soft Computing ( IF 8.7 ) Pub Date : 2020-03-13 , DOI: 10.1016/j.asoc.2020.106210 Álvaro S. Hervella , José Rouco , Jorge Novo , Marcos Ortega
|
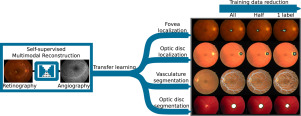
Deep learning is becoming the reference paradigm for approaching many computer vision problems. Nevertheless, the training of deep neural networks typically requires a significantly large amount of annotated data, which is not always available. A proven approach to alleviate the scarcity of annotated data is transfer learning. However, in practice, the use of this technique typically relies on the availability of additional annotations, either from the same or natural domain. We propose a novel alternative that allows to apply transfer learning from unlabelled data of the same domain, which consists in the use of a multimodal reconstruction task. A neural network trained to generate one image modality from another must learn relevant patterns from the images to successfully solve the task. These learned patterns can then be used to solve additional tasks in the same domain, reducing the necessity of a large amount of annotated data.
In this work, we apply the described idea to the localization and segmentation of the most important anatomical structures of the eye fundus in retinography. The objective is to reduce the amount of annotated data that is required to solve the different tasks using deep neural networks. For that purpose, a neural network is pre-trained using the self-supervised multimodal reconstruction of fluorescein angiography from retinography. Then, the network is fine-tuned on the different target tasks performed on the retinography. The obtained results demonstrate that the proposed self-supervised transfer learning strategy leads to state-of-the-art performance in all the studied tasks with a significant reduction of the required annotations.
中文翻译:
使用自我监督的多模式重建从稀缺的注释数据中学习视网膜解剖
深度学习正在成为解决许多计算机视觉问题的参考范例。尽管如此,深度神经网络的训练通常需要大量的注释数据,而这些注释数据并不总是可用。减轻已批注数据稀缺性的一种行之有效的方法是转移学习。但是,实际上,此技术的使用通常依赖于来自相同或自然域的其他注释的可用性。我们提出了一种新颖的替代方案,该方案允许从相同域的未标记数据中应用转移学习,这包括使用多模式重构任务。经过训练以从另一个图像生成一个图像模态的神经网络必须从图像中学习相关模式才能成功解决任务。
在这项工作中,我们将所描述的想法应用于视网膜成像中眼底最重要的解剖结构的定位和分割。目的是减少使用深度神经网络解决不同任务所需的注释数据量。为此,使用自检的荧光素血管造影的自监督多峰重建技术来训练神经网络。然后,对在视网膜成像上执行的不同目标任务进行微调。获得的结果表明,所提出的自我监督的转移学习策略在所有研究任务中都具有最先进的性能,并且显着减少了所需的注释。

























 京公网安备 11010802027423号
京公网安备 11010802027423号