Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2020-03-06 , DOI: 10.1016/j.jbi.2020.103396 Noha S Tawfik 1 , Marco R Spruit 2
|
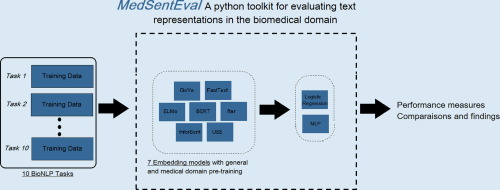
Text representations ar one of the main inputs to various Natural Language Processing (NLP) methods. Given the fast developmental pace of new sentence embedding methods, we argue that there is a need for a unified methodology to assess these different techniques in the biomedical domain. This work introduces a comprehensive evaluation of novel methods across ten medical classification tasks. The tasks cover a variety of BioNLP problems such as semantic similarity, question answering, citation sentiment analysis and others with binary and multi-class datasets. Our goal is to assess the transferability of different sentence representation schemes to the medical and clinical domain. Our analysis shows that embeddings based on Language Models which account for the context-dependent nature of words, usually outperform others in terms of performance. Nonetheless, there is no single embedding model that perfectly represents biomedical and clinical texts with consistent performance across all tasks. This illustrates the need for a more suitable bio-encoder. Our MedSentEval source code, pre-trained embeddings and examples have been made available on GitHub.
中文翻译:
评价生物医学文本的句子表示:方法和实验结果
文本表示是各种自然语言处理(NLP)方法的主要输入之一。鉴于新句子嵌入方法的快速发展速度,我们认为需要一种统一的方法来评估生物医学领域中的这些不同技术。这项工作介绍了十种医学分类任务中对新方法的全面评估。这些任务涵盖了各种BioNLP问题,例如语义相似性,问题回答,引文情感分析以及其他具有二进制和多类数据集的问题。我们的目标是评估不同句子表示方案在医学和临床领域的可移植性。我们的分析表明,基于语言模型的嵌入说明了单词的上下文相关性质,在性能方面通常优于其他语言。但是,没有一个单一的嵌入模型可以完美地代表生物医学和临床文本,并且在所有任务中均具有一致的性能。这说明了对更合适的生物编码器的需求。我们的MedSentEval源代码,经过预训练的嵌入和示例已在GitHub上提供。

























 京公网安备 11010802027423号
京公网安备 11010802027423号