Future Generation Computer Systems ( IF 7.5 ) Pub Date : 2020-03-04 , DOI: 10.1016/j.future.2020.02.076 Zhaonian Tan , Weixing Ji , Jianhua Gao , Yueyan Zhao , Akrem Benatia , Yizhuo Wang , Feng Shi
|
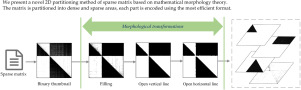
Sparse matrix is any matrix with enough zeros that it pays to take advantage of them. The computational efficiency of sparse matrix–vector multiplication (SpMV) is significantly influenced by the distribution of non-zero elements in sparse matrix, which is not fully exploited by traditional one-dimensional and two-dimensional partitioning approaches. In this paper, we present a novel two-dimensional partitioning method based on mathematical morphology theory. The matrix is partitioned into dense and sparse areas utilizing some basic morphological transformations, including dilatation, filling, opening, and skeletonization. These dense areas are classified as rectangle, triangle, and diagonal according to their morphological features. We also propose a new MMSparse (Mathematical Morphological Sparse) format that stores each type of shapes in the most efficient format instead of one format for an entire matrix. We select different types of matrices from the SuiteSparse Matrix Collection and conduct a series of experiments on NVIDIA GTX 1080Ti GPU. The experimental results show that our approach achieves average speedup 2.47x over the best performance of the cuSPARSE library kernel, 2.54x over BCSR, 1.48x over yaSpMV, 1.85x over CSR5, 1.35x over the one-dimensional partition.
中文翻译:
MMSparse:基于数学形态学的稀疏矩阵的二维划分
稀疏矩阵是具有足以使用它们的零的任何矩阵。稀疏矩阵-矢量乘法(SpMV)的计算效率受到稀疏矩阵中非零元素分布的显着影响,传统的一维和二维分区方法并未充分利用该效率。在本文中,我们提出了一种基于数学形态学理论的新型二维划分方法。利用一些基本的形态转换,包括膨胀,填充,打开和骨架化,将矩阵划分为密集和稀疏的区域。这些密集区域根据其形态特征分为矩形,三角形和对角线。我们还提出了一种新的MMSparse(数学形态学稀疏)格式,该格式以最有效的格式而不是整个矩阵的一种格式存储每种形状。我们从SuiteSparse Matrix Collection中选择不同类型的矩阵,并在NVIDIA GTX 1080Ti GPU上进行一系列实验。实验结果表明,我们的方法比cuSPARSE库内核的最佳性能平均提高了2.47倍,比BCSR提升了2.54倍,比yaSpMV提升了1.48倍,比CSR5提升了1.85倍,比一维分区提高了1.35倍。


























 京公网安备 11010802027423号
京公网安备 11010802027423号