当前位置:
X-MOL 学术
›
Atmos. Environ.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Ensemble averaging based assessment of spatiotemporal variations in ambient PM2.5 concentrations over Delhi, India, during 2010–2016
Atmospheric Environment ( IF 5 ) Pub Date : 2020-03-01 , DOI: 10.1016/j.atmosenv.2020.117309 Siddhartha Mandal 1, 2 , Kishore K Madhipatla 1 , Sarath Guttikunda 3, 4 , Itai Kloog 5 , Dorairaj Prabhakaran 1, 2, 6 , Joel D Schwartz 7 ,
Atmospheric Environment ( IF 5 ) Pub Date : 2020-03-01 , DOI: 10.1016/j.atmosenv.2020.117309 Siddhartha Mandal 1, 2 , Kishore K Madhipatla 1 , Sarath Guttikunda 3, 4 , Itai Kloog 5 , Dorairaj Prabhakaran 1, 2, 6 , Joel D Schwartz 7 ,
Affiliation
|
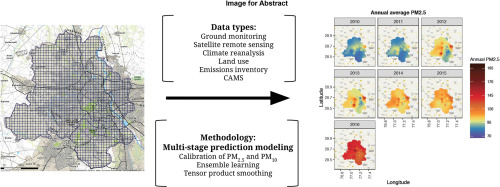
Elevated levels of ambient air pollution has been implicated as a major risk factor for morbidities and premature mortality in India, with particularly high concentrations of particulate matter in the Indo-Gangetic plain. High resolution spatiotemporal estimates of such exposures are critical to assess health effects at an individual level. This article retrospectively assesses daily average PM2.5 exposure at 1 km × 1 km grids in Delhi, India from 2010-2016, using multiple data sources and ensemble averaging approaches. We used a multi-stage modeling exercise involving satellite data, land use variables, reanalysis based meteorological variables and population density. A calibration regression was used to model PM2.5: PM10 to counter the sparsity of ground monitoring data. The relationship between PM2.5 and its spatiotemporal predictors was modeled using six learners; generalized additive models, elastic net, support vector regressions, random forests, neural networks and extreme gradient boosting. Subsequently, these predictions were combined under a generalized additive model framework using a tensor product based spatial smoothing. Overall cross-validated prediction accuracy of the model was 80% over the study period with high spatial model accuracy and predicted annual average concentrations ranging from 87 to 138 μg/m3. Annual average root mean squared errors for the ensemble averaged predictions were in the range 39.7-62.7 μg/m3 with prediction bias ranging between 4.6-11.2 μg/m3. In addition, tree based learners such as random forests and extreme gradient boosting outperformed other algorithms. Our findings indicate important seasonal and geographical differences in particulate matter concentrations within Delhi over a significant period of time, with meteorological and land use features that discriminate most and least polluted regions. This exposure assessment can be used to estimate dose response relationships more accurately over a wide range of particulate matter concentrations.
中文翻译:

基于集合平均的 2010-2016 年印度德里环境 PM2.5 浓度时空变化评估
环境空气污染水平升高被认为是印度发病和过早死亡的主要风险因素,特别是印度恒河平原的颗粒物浓度特别高。对此类暴露的高分辨率时空估计对于评估个体水平的健康影响至关重要。本文使用多个数据源和集合平均方法,回顾性评估了 2010 年至 2016 年印度德里 1 km × 1 km 网格的每日平均 PM2.5 暴露量。我们使用了多阶段建模练习,涉及卫星数据、土地利用变量、基于气象变量和人口密度的再分析。使用校准回归对 PM2.5: PM10 进行建模,以应对地面监测数据的稀疏性。使用 6 个学习器对 PM2.5 及其时空预测因子之间的关系进行建模;广义加性模型、弹性网络、支持向量回归、随机森林、神经网络和极限梯度提升。随后,使用基于张量积的空间平滑将这些预测组合在广义加性模型框架下。在研究期间,该模型的总体交叉验证预测精度为 80%,空间模型精度较高,预测年平均浓度范围为 87 至 138 μg/m3。整体平均预测的年平均均方根误差在 39.7-62.7 μg/m3 范围内,预测偏差在 4.6-11.2 μg/m3 之间。此外,基于树的学习器(例如随机森林和极限梯度提升)的性能优于其他算法。我们的研究结果表明,在相当长的一段时间内,德里颗粒物浓度存在重要的季节性和地理差异,气象和土地利用特征区分了污染最严重和最少的地区。这种暴露评估可用于更准确地估计大范围颗粒物浓度的剂量响应关系。
更新日期:2020-03-01
中文翻译:
基于集合平均的 2010-2016 年印度德里环境 PM2.5 浓度时空变化评估
环境空气污染水平升高被认为是印度发病和过早死亡的主要风险因素,特别是印度恒河平原的颗粒物浓度特别高。对此类暴露的高分辨率时空估计对于评估个体水平的健康影响至关重要。本文使用多个数据源和集合平均方法,回顾性评估了 2010 年至 2016 年印度德里 1 km × 1 km 网格的每日平均 PM2.5 暴露量。我们使用了多阶段建模练习,涉及卫星数据、土地利用变量、基于气象变量和人口密度的再分析。使用校准回归对 PM2.5: PM10 进行建模,以应对地面监测数据的稀疏性。使用 6 个学习器对 PM2.5 及其时空预测因子之间的关系进行建模;广义加性模型、弹性网络、支持向量回归、随机森林、神经网络和极限梯度提升。随后,使用基于张量积的空间平滑将这些预测组合在广义加性模型框架下。在研究期间,该模型的总体交叉验证预测精度为 80%,空间模型精度较高,预测年平均浓度范围为 87 至 138 μg/m3。整体平均预测的年平均均方根误差在 39.7-62.7 μg/m3 范围内,预测偏差在 4.6-11.2 μg/m3 之间。此外,基于树的学习器(例如随机森林和极限梯度提升)的性能优于其他算法。我们的研究结果表明,在相当长的一段时间内,德里颗粒物浓度存在重要的季节性和地理差异,气象和土地利用特征区分了污染最严重和最少的地区。这种暴露评估可用于更准确地估计大范围颗粒物浓度的剂量响应关系。

























 京公网安备 11010802027423号
京公网安备 11010802027423号