PLOS ONE ( IF 3.7 ) Pub Date : 2018-09-21 , DOI: 10.1371/journal.pone.0204399 Hugh J W Sturrock 1 , Katelyn Woolheater 2 , Adam F Bennett 1 , Ricardo Andrade-Pacheco 1 , Alemayehu Midekisa 1
|
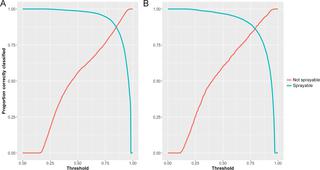
Having accurate maps depicting the locations of residential buildings across a region benefits a range of sectors. This is particularly true for public health programs focused on delivering services at the household level, such as indoor residual spraying with insecticide to help prevent malaria. While open source data from OpenStreetMap (OSM) depicting the locations and shapes of buildings is rapidly improving in terms of quality and completeness globally, even in settings where all buildings have been mapped, information on whether these buildings are residential, commercial or another type is often only available for a small subset. Using OSM building data from Botswana and Swaziland, we identified buildings for which ‘type’ was indicated, generated via on the ground observations, and classified these into two classes, “sprayable” and “not-sprayable”. Ensemble machine learning, using building characteristics such as size, shape and proximity to neighbouring features, was then used to form a model to predict which of these 2 classes every building in these two countries fell into. Results show that an ensemble machine learning approach performed marginally, but statistically, better than the best individual model and that using this ensemble model we were able to correctly classify >86% (using independent test data) of structures correctly as sprayable and not-sprayable across both countries.
中文翻译:
使用机器学习从开源远程枚举数据预测住宅结构
拥有描绘一个地区住宅建筑位置的准确地图对一系列行业都有好处。对于侧重于在家庭层面提供服务的公共卫生计划尤其如此,例如室内滞留喷洒杀虫剂以帮助预防疟疾。尽管来自 OpenStreetMap (OSM) 的描绘建筑物位置和形状的开源数据在全球范围内的质量和完整性方面正在迅速提高,但即使在所有建筑物都已绘制地图的环境中,有关这些建筑物是住宅、商业还是其他类型的信息仍然存在。通常仅适用于一小部分。使用来自博茨瓦纳和斯威士兰的 OSM 建筑数据,我们确定了通过地面观察生成的指示“类型”的建筑物,并将其分为两类:“可喷涂”和“不可喷涂”。然后使用集成机器学习,利用大小、形状和与邻近特征的接近程度等建筑特征来形成模型,以预测这两个国家的每座建筑属于这两个类别中的哪一个。结果表明,集成机器学习方法的性能稍差,但从统计角度来看,优于最佳单个模型,并且使用该集成模型,我们能够将 > 86%(使用独立测试数据)的结构正确分类为可喷涂和不可喷涂跨越两国。

























 京公网安备 11010802027423号
京公网安备 11010802027423号