PLOS ONE ( IF 3.7 ) Pub Date : 2018-03-19 , DOI: 10.1371/journal.pone.0194608 Rick J. Jansen , Bruce H. Alexander , Richard B. Hayes , Anthony B. Miller , Sholom Wacholder , Timothy R. Church
|
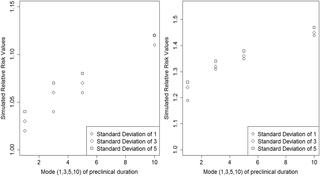
When some individuals are screen-detected before the beginning of the study, but otherwise would have been diagnosed symptomatically during the study, this results in different case-ascertainment probabilities among screened and unscreened participants, referred to here as lead-time-biased case-ascertainment (LTBCA). In fact, this issue can arise even in risk-factor studies nested within a randomized screening trial; even though the screening intervention is randomly allocated to trial arms, there is no randomization to potential risk-factors and uptake of screening can differ by risk-factor strata. Under the assumptions that neither screening nor the risk factor affects underlying incidence and no other forms of bias operate, we simulate and compare the underlying cumulative incidence and that observed in the study due to LTBCA. The example used will be constructed from the randomized Prostate, Lung, Colorectal, and Ovarian cancer screening trial. The derived mathematical model is applied to simulating two nested studies to evaluate the potential for screening bias in observational lung cancer studies. Because of differential screening under plausible assumptions about preclinical incidence and duration, the simulations presented here show that LTBCA due to chest x-ray screening can significantly increase the estimated risk of lung cancer due to smoking by 1% and 50%. Traditional adjustment methods cannot account for this bias, as the influence screening has on observational study estimates involves events outside of the study observation window (enrollment and follow-up) that change eligibility for potential participants, thus biasing case ascertainment.
中文翻译:
确定病例偏倚的数学模型:应用于嵌套在随机筛查试验中的病例对照研究
如果在研究开始之前对某些个体进行了筛查,但在研究过程中可能有症状地被诊断出,则这会导致被筛查和未筛查参与者的病例确定概率不同,在此称为前置时间偏向病例-确定性(LTBCA)。实际上,即使在随机筛查试验中嵌套的风险因素研究中也可能出现此问题。即使筛查干预措施是随机分配给试验组的,也没有对潜在风险因素的随机分配,并且筛查的摄取可能因风险因素分层而异。在筛选和风险因素均不影响潜在发病率且没有其他形式的偏见起作用的假设下,我们模拟并比较了潜在累积发病率和由于LTBCA而在研究中观察到的累积发病率。所使用的示例将从随机的前列腺癌,肺癌,结肠直肠癌和卵巢癌筛查试验中构建。派生的数学模型用于模拟两个嵌套研究,以评估观察性肺癌研究中筛选偏倚的潜力。由于在关于临床前发生率和持续时间的合理假设下进行了差异筛查,因此此处提供的模拟结果表明,由于进行胸部X线筛查而产生的LTBCA可以显着增加吸烟引起的肺癌风险估计值,分别为1%和50%。传统的调整方法无法解决这种偏见,因为筛查对观察性研究估计值的影响涉及研究观察窗之外的事件(入组和随访),这些事件会改变潜在参与者的资格,从而使病例确定性产生偏差。


























 京公网安备 11010802027423号
京公网安备 11010802027423号