当前位置:
X-MOL 学术
›
Chem. Bio. Drug Des.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
In silico ligand‐based modeling of hBACE‐1 inhibitors
Chemical Biology & Drug Design ( IF 3 ) Pub Date : 2017-12-10 , DOI: 10.1111/cbdd.13147 Govindan Subramanian 1 , Gennady Poda 2, 3
Chemical Biology & Drug Design ( IF 3 ) Pub Date : 2017-12-10 , DOI: 10.1111/cbdd.13147 Govindan Subramanian 1 , Gennady Poda 2, 3
Affiliation
|
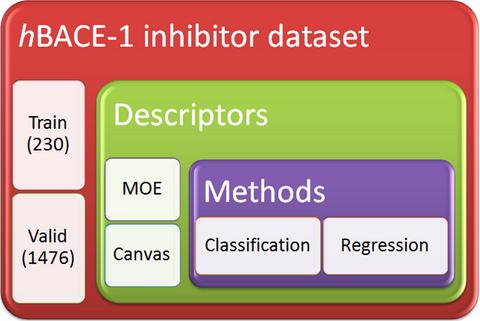
Alzheimer's disease is a chronic neurodegenerative disease affecting more than 30 million people worldwide. Development of small molecule inhibitors of human β‐secretase 1 (hBACE‐1) is being the focus of pharmaceutical industry for the past 15–20 years. Here, we successfully applied multiple ligand‐based in silico modeling techniques to understand the inhibitory activities of a diverse set of small molecule hBACE‐1 inhibitors reported in the scientific literature. Strikingly, the use of only a small subset of 230 (13%) molecules allowed us to develop quality models that performed reasonably well on the validation set of 1,476 (87%) inhibitors. Varying the descriptor sets and the complexity of the modeling techniques resulted in only minor improvements to the model's performance. The current results demonstrate that predictive models can be built by choosing appropriate modeling techniques in spite of using small datasets consisting of diverse chemical classes, a scenario typical in triaging of high‐throughput screening results to identify false negatives. We hope that these encouraging results will help the community to develop more predictive models that would support research efforts for the debilitating Alzheimer's disease. Additionally, the integrated diversity of the techniques employed will stimulate scientists in the field to use in silico statistical modeling techniques like these to derive better models to help advance the drug discovery projects faster.
中文翻译:

基于计算机配体的hBACE-1抑制剂建模
阿尔茨海默氏病是一种慢性神经退行性疾病,影响全世界超过3000万人。在过去的15至20年中,人类β-分泌酶1(hBACE-1)的小分子抑制剂的开发一直是制药业关注的焦点。在这里,我们成功地应用了多种基于配体的计算机模拟技术,以了解科学文献中报道的多种多样的小分子hBACE-1抑制剂的抑制活性。令人惊讶的是,仅使用一小部分230(13%)分子使我们能够开发出质量模型,该模型在1,476个(87%)抑制剂的验证集上表现良好。改变描述符集和建模技术的复杂性只会导致模型性能的微小改进。目前的结果表明,尽管使用了由不同化学类别组成的小型数据集,但仍可以通过选择适当的建模技术来构建预测模型,这是对高通量筛选结果进行分类以识别假阴性的典型情况。我们希望这些令人鼓舞的结果将有助于社区开发更多的预测模型,以支持衰弱性阿尔茨海默氏病的研究工作。此外,所采用技术的综合多样性将刺激该领域的科学家使用诸如此类的计算机统计模型技术来得出更好的模型,以帮助更快地推进药物发现项目。在高通量筛选结果分类中识别假阴性的典型场景。我们希望这些令人鼓舞的结果将有助于社区开发更多的预测模型,以支持衰弱性阿尔茨海默氏病的研究工作。此外,所采用技术的综合多样性将刺激该领域的科学家使用诸如此类的计算机统计模型技术来得出更好的模型,以帮助更快地推进药物发现项目。在高通量筛选结果分类中识别假阴性的典型场景。我们希望这些令人鼓舞的结果将有助于社区开发更多的预测模型,以支持衰弱性阿尔茨海默氏病的研究工作。此外,所采用技术的综合多样性将刺激该领域的科学家使用诸如此类的计算机统计模型技术来得出更好的模型,以帮助更快地推进药物发现项目。
更新日期:2017-12-10
中文翻译:
基于计算机配体的hBACE-1抑制剂建模
阿尔茨海默氏病是一种慢性神经退行性疾病,影响全世界超过3000万人。在过去的15至20年中,人类β-分泌酶1(hBACE-1)的小分子抑制剂的开发一直是制药业关注的焦点。在这里,我们成功地应用了多种基于配体的计算机模拟技术,以了解科学文献中报道的多种多样的小分子hBACE-1抑制剂的抑制活性。令人惊讶的是,仅使用一小部分230(13%)分子使我们能够开发出质量模型,该模型在1,476个(87%)抑制剂的验证集上表现良好。改变描述符集和建模技术的复杂性只会导致模型性能的微小改进。目前的结果表明,尽管使用了由不同化学类别组成的小型数据集,但仍可以通过选择适当的建模技术来构建预测模型,这是对高通量筛选结果进行分类以识别假阴性的典型情况。我们希望这些令人鼓舞的结果将有助于社区开发更多的预测模型,以支持衰弱性阿尔茨海默氏病的研究工作。此外,所采用技术的综合多样性将刺激该领域的科学家使用诸如此类的计算机统计模型技术来得出更好的模型,以帮助更快地推进药物发现项目。在高通量筛选结果分类中识别假阴性的典型场景。我们希望这些令人鼓舞的结果将有助于社区开发更多的预测模型,以支持衰弱性阿尔茨海默氏病的研究工作。此外,所采用技术的综合多样性将刺激该领域的科学家使用诸如此类的计算机统计模型技术来得出更好的模型,以帮助更快地推进药物发现项目。在高通量筛选结果分类中识别假阴性的典型场景。我们希望这些令人鼓舞的结果将有助于社区开发更多的预测模型,以支持衰弱性阿尔茨海默氏病的研究工作。此外,所采用技术的综合多样性将刺激该领域的科学家使用诸如此类的计算机统计模型技术来得出更好的模型,以帮助更快地推进药物发现项目。

























 京公网安备 11010802027423号
京公网安备 11010802027423号