当前位置:
X-MOL 学术
›
ACS Comb. Sci.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Poisson Statistics of Combinatorial Library Sampling Predict False Discovery Rates of Screening
ACS Combinatorial Science ( IF 3.903 ) Pub Date : 2017-07-26 00:00:00 , DOI: 10.1021/acscombsci.7b00061 Andrew B. MacConnell 1 , Brian M. Paegel 1
ACS Combinatorial Science ( IF 3.903 ) Pub Date : 2017-07-26 00:00:00 , DOI: 10.1021/acscombsci.7b00061 Andrew B. MacConnell 1 , Brian M. Paegel 1
Affiliation
|
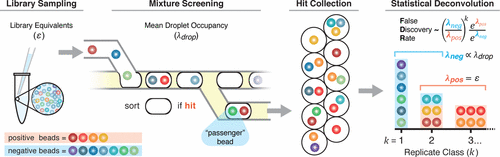
Microfluidic droplet-based screening of DNA-encoded one-bead-one-compound combinatorial libraries is a miniaturized, potentially widely distributable approach to small molecule discovery. In these screens, a microfluidic circuit distributes library beads into droplets of activity assay reagent, photochemically cleaves the compound from the bead, then incubates and sorts the droplets based on assay result for subsequent DNA sequencing-based hit compound structure elucidation. Pilot experimental studies revealed that Poisson statistics describe nearly all aspects of such screens, prompting the development of simulations to understand system behavior. Monte Carlo screening simulation data showed that increasing mean library sampling (ε), mean droplet occupancy, or library hit rate all increase the false discovery rate (FDR). Compounds identified as hits on k > 1 beads (the replicate k class) were much more likely to be authentic hits than singletons (k = 1), in agreement with previous findings. Here, we explain this observation by deriving an equation for authenticity, which reduces to the product of a library sampling bias term (exponential in k) and a sampling saturation term (exponential in ε) setting a threshold that the k-dependent bias must overcome. The equation thus quantitatively describes why each hit structure’s FDR is based on its k class, and further predicts the feasibility of intentionally populating droplets with multiple library beads, assaying the micromixtures for function, and identifying the active members by statistical deconvolution.
中文翻译:

组合图书馆抽样的泊松统计预测筛选的错误发现率
基于微流体液滴的DNA编码的单珠一化合物组合文库筛选是一种小型化的,可能广泛分布的小分子发现方法。在这些筛选中,微流控电路将文库珠子分散到活性测定试剂的液滴中,从珠子中光化学裂解化合物,然后根据测定结果孵育并分类液滴,以用于后续基于DNA测序的命中化合物结构阐明。初步实验研究表明,泊松统计信息几乎描述了此类屏幕的所有方面,从而促进了模拟的发展,以了解系统行为。蒙特卡洛筛选模拟数据表明,平均文库采样率(ε),平均液滴占有率或文库命中率的提高都增加了错误发现率(FDR)。ķ > 1个珠(复制ķ类)为多少更可能比单身真实命中(ķ = 1),与先前的研究结果一致。在这里,我们通过推导真实性方程来解释这种观察,该方程可简化为库采样偏差项(k的指数)和采样饱和度项(ε的指数)的乘积,设置了依赖于k的偏差必须克服的阈值。因此,该方程式定量描述了为什么每个碰撞结构的FDR基于其k 一类,并进一步预测了用多个文库珠有意填充小滴,分析微混合物的功能并通过统计反卷积识别活性成员的可行性。
更新日期:2017-07-28
中文翻译:
组合图书馆抽样的泊松统计预测筛选的错误发现率
基于微流体液滴的DNA编码的单珠一化合物组合文库筛选是一种小型化的,可能广泛分布的小分子发现方法。在这些筛选中,微流控电路将文库珠子分散到活性测定试剂的液滴中,从珠子中光化学裂解化合物,然后根据测定结果孵育并分类液滴,以用于后续基于DNA测序的命中化合物结构阐明。初步实验研究表明,泊松统计信息几乎描述了此类屏幕的所有方面,从而促进了模拟的发展,以了解系统行为。蒙特卡洛筛选模拟数据表明,平均文库采样率(ε),平均液滴占有率或文库命中率的提高都增加了错误发现率(FDR)。ķ > 1个珠(复制ķ类)为多少更可能比单身真实命中(ķ = 1),与先前的研究结果一致。在这里,我们通过推导真实性方程来解释这种观察,该方程可简化为库采样偏差项(k的指数)和采样饱和度项(ε的指数)的乘积,设置了依赖于k的偏差必须克服的阈值。因此,该方程式定量描述了为什么每个碰撞结构的FDR基于其k 一类,并进一步预测了用多个文库珠有意填充小滴,分析微混合物的功能并通过统计反卷积识别活性成员的可行性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号